2023-11-29 60th Class
Convolutional Neural Network - GoogLeNet
#️⃣ GoogLeNet의 아이디어
[배경] 딥러닝 모델의 depth가 깊어질 때 backpropagation이 잘 되지 않는 문제가 발생함
[아이디어1] backpropagation이 진행되는 동시에, 중간에서 backpropagation을 추가 (전미분과 관련)
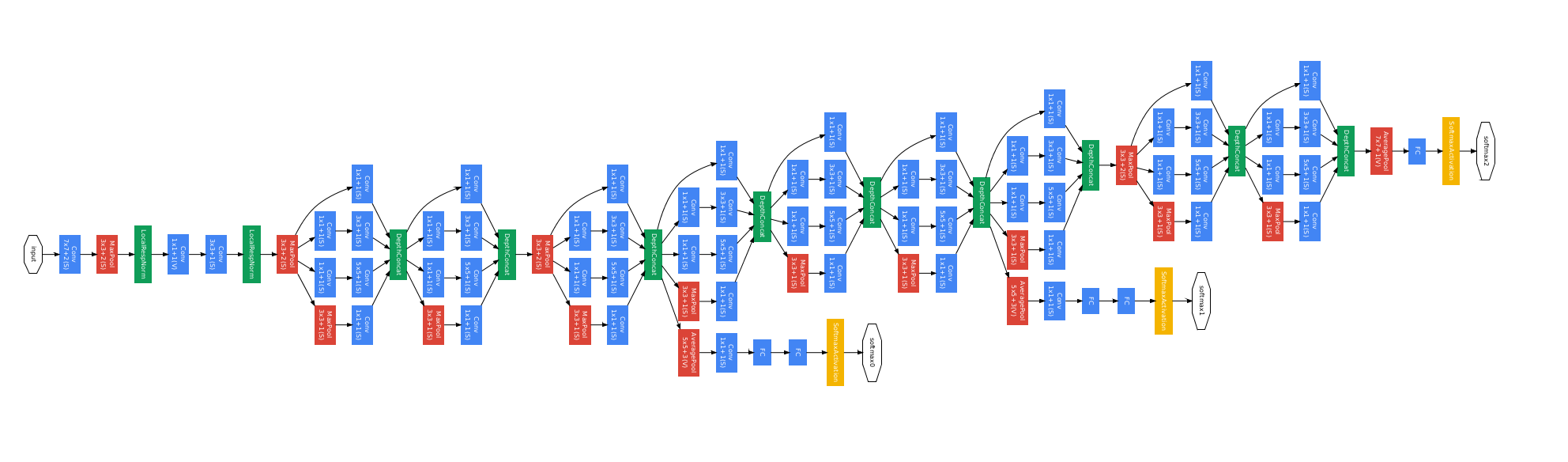
GoogLeNet은 Branch 개념을 사용한 모델
(branch가 있는 경우에는 nn.Sequential을 사용할 수 없음)
[아이디어2] 한 번의 합성곱층을 통과할 때, filter를 여러개를 통과할 수 있게 함
Figure2 : Inception module
| (a) Inception module, naive version | (b) Inception module with dimension reductions |
|---|---|
 |
 |
#️⃣ Inception Module (naive version)
[Inception Module (naive ver.) tensor size 계산 방법]
[Step 0] input data: 이전 레이어에서의 input이 (192, 100, 100)이라고 가정
- GoogLeNet에서는 브랜치 내에서 conv, pooling층 모두 이미지 사이즈를 변환시키지 않음
- 이미지사이즈가 변하지 않는 kernel:padding pair -> (3:1, 5:2, 7:3 …)
[Step 1] branch 연산: 여러개의 convolutional layers + pooling층 연산
| 브랜치 | 커널크기 | 아웃채널 | 파라미터 | 아웃풋 사이즈 |
|---|---|---|---|---|
| 1번째 | 1x1 conv | 64 | in=192, out=64, kernel=1, padding=0 | (64, 100, 100) |
| 2번째 | 3x3 conv | 128 | in=192, out=128, kernel=3, padding=1 | (128, 100, 100) |
| 3번째 | 5x5 conv | 32 | in=192, out=32, kernel=5, padding=2 | (32, 100, 100) |
| pooling | 3x3 max pool | kernel=3, padding=1, stride=1 | (192, 100, 100) |
(googlenet에서는 이미지 사이즈를 유지하는 pooling을 함)
[Step 2] 브랜치 병합: cnn+pool 레이어 concatenate
concat은 channel 기준으로 수행할 것
(예시1)
데이터 1개일 경우 axis=0으로 concat > (416, 100, 100)
- (z, y, x) -> (0, 1, 2)
- axis=0으로 합치면 (64+128+32+192, 100, 100)이 됨
(예시2)
batchsize가 있을 경우 axis=1로 concat
- (a, z, y, x) -> (0, 1, 2)
- axis=1로 합치면 (B, 64,+128+32+192, 100, 100)이 됨
Inception Module Process
| branch | function |
|---|---|
| branch1 | ConvBlock(in_channels=in_channels, out_channels=ch1x1, kernel_size=1, padding=0) |
| out_branch1 | branch1(input_tensor) |
| branch2 | ConvBlock(in_channels=in_channels, out_channels=ch3x3, kernel_size=3, padding=1) |
| out_branch2 | branch2(64, 100, 100) |
| branch3 | ConvBlock(in_channels=in_channels, out_channels=ch5x5, kernel_size=5, padding=2) |
| out_branch3 | branch3(128, 100, 100) |
| branch4 | nn.MaxPool2d(kernel_size=3, padding=1, stride=1) |
| out_branch4 | branch4(32, 100, 100) |
| out_inception | concat(branch1, branch2, brahch3, branch4, axis=0) |
정리
- GoogLeNet에서는 브랜치 계산 시 이미지 사이즈가 변동되지 않음
- 브랜치 계산 후에는 concat함
#️⃣ Inception Module with Dimension Reductions
1x1 conv를 먼저 실행해서
- 이미지의 채널수를 줄이는 효과가 생김
- 1x1 conv 는 fully connected layer과 동일한 수행이기때문에
- fully connected layer을 통과하면서 -> non-linearity 추가하는 효과 (모델의 복잡성 더하기)
[Inception Module (dimension reduction ver.) tensor size 계산 방법]
[Step 0] input data: 이전 레이어에서의 input이 (192, 100, 100)이라고 가정
Branch 2 계산
ch3x3red, ch3x3 = 96, 128
branch2 = nn.Sequential(
ConvBlock(in_channels=192, out_channels=ch3x3red, kernel_size=1, padding=0, stride=1),
ConvBlock(in_channels=ch3x3red, out_channels=ch3x3, kernel_size=3, padding=1, stride=1)
)
out_branch2 = branch2(input_tensor)
print("Branch2: ", out_branch2.shape)
# Brahcn2: torch.Size([128, 100, 100])
Branch 3 계산
ch5x5red, ch5x5 = 16, 32
branch3 = nn.Sequential(
ConvBlock(in_channels=192, out_channels=ch5x5red, kernel_size=1, padding=0, stride=1),
ConvBlock(in_channels=ch5x5red, out_channels=ch5x5, kernel_size=5, padding=2, stride=1)
)
out_branch3 = branch3(input_tensor)
print("Branch3: ", out_branch3.shape)
# Brahcn3: torch.Size([32, 100, 100])
Branch 4 (pooling) 계산
pool_proj = 32
branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, padding=1, stride=1),
ConvBlock(in_channels=192, out_channels=pool_proj, kernel_size=1)
)
out_branch4 = branch3(input_tensor)
print("Branch4: ", out_branch4.shape)
# Brahcn4: torch.Size([32, 100, 100])

- nn.MaxPool2d의 기본 stride는 2 이기때문에, Inception 블록에 pooling을 설정할 때는 stride를 꼭 1로 설정해야 함
#️⃣ GoogLeNet 구현
아래의 아키텍처와 표를 참고하여 GoogLeNet을 Pytorch로 구현

code
import torch
import torch.nn as nn
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, padding=0, stride=1):
super(ConvBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, padding=padding, stride=stride)
self.conv1_act = nn.ReLU()
def forward(self, x):
x = self.conv1(x)
x = self.conv1_act(x)
return x
class InceptionNaive(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3, ch5x5):
# input channel 수와 1x1, 3x3, 5x5 branch의 output channel 수를 입력받음
super(InceptionNaive, self).__init__()
self.branch1 = ConvBlock(in_channels=in_channels, out_channels=ch1x1,
kernel_size=1, padding=0)
self.branch2 = ConvBlock(in_channels=in_channels, out_channels=ch3x3,
kernel_size=3, padding=1)
self.branch3 = ConvBlock(in_channels=in_channels, out_channels=ch5x5,
kernel_size=5, padding=2)
self.branch4 = nn.MaxPool2d(kernel_size=3, padding=1, stride=1)
def forward(self, x):
concat_axis = 1 if x.dim() == 4 else 0
out_branch1 = self.branch1.forward(x)
out_branch2 = self.branch2.forward(x)
out_branch3 = self.branch3.forward(x)
out_branch4 = self.branch4.forward(x)
to_concat = (out_branch1, out_branch2, out_branch3, out_branch4)
x = torch.cat(tensors=to_concat, dim=concat_axis)
return x
class Inception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
super(Inception, self).__init__()
self.branch1 = ConvBlock(in_channels=in_channels, out_channels=ch1x1,
kernel_size=1, padding=0)
self.branch2 = nn.Sequential(
ConvBlock(in_channels=in_channels, out_channels=ch3x3red,
kernel_size=1, padding=0),
ConvBlock(in_channels=ch3x3red, out_channels=ch3x3,
kernel_size=3, padding=1))
self.branch3 = nn.Sequential(
ConvBlock(in_channels=in_channels, out_channels=ch5x5red,
kernel_size=1, padding=0),
ConvBlock(in_channels=ch5x5red, out_channels=ch5x5,
kernel_size=5, padding=2))
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, padding=1, stride=1),
ConvBlock(in_channels=in_channels, out_channels=pool_proj,
kernel_size=1, padding=0)
)
def forward(self, x):
concat_axis = 1 if x.dim() == 4 else 0
out_branch1 = self.branch1.forward(x)
out_branch2 = self.branch2.forward(x)
out_branch3 = self.branch3.forward(x)
out_branch4 = self.branch4.forward(x)
to_concat = (out_branch1, out_branch2, out_branch3, out_branch4)
x = torch.cat(tensors=to_concat, dim=concat_axis)
return x
class GoogLeNet(nn.Module):
def __init__(self, in_channels):
super(GoogLeNet, self).__init__()
# 1
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=64, kernel_size=7, padding=3, stride=2)
self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 2
self.conv2_red = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=1, padding=0, stride=1)
self.conv2 = nn.Conv2d(in_channels=64, out_channels=192, kernel_size=3, padding=1, stride=1)
self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 3
self.icp_3a = Inception(in_channels=192, ch1x1=64, ch3x3red=96, ch3x3=128,
ch5x5red=16, ch5x5=32, pool_proj=32)
self.icp_3b = Inception(in_channels=256, ch1x1=128, ch3x3red=128, ch3x3=192,
ch5x5red=32, ch5x5=96, pool_proj=64)
self.maxpool3 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 4
self.icp_4a = Inception(in_channels=480, ch1x1=192, ch3x3red=96, ch3x3=208,
ch5x5red=16, ch5x5=48, pool_proj=64)
self.icp_4b = Inception(in_channels=512, ch1x1=160, ch3x3red=112, ch3x3=224,
ch5x5red=24, ch5x5=64, pool_proj=64)
self.icp_4c = Inception(in_channels=512, ch1x1=128, ch3x3red=128, ch3x3=256,
ch5x5red=24, ch5x5=64, pool_proj=64)
self.icp_4d = Inception(in_channels=512, ch1x1=112, ch3x3red=144, ch3x3=288,
ch5x5red=32, ch5x5=64, pool_proj=64)
self.icp_4e = Inception(in_channels=528, ch1x1=256, ch3x3red=160, ch3x3=320,
ch5x5red=32, ch5x5=128, pool_proj=128)
self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 5
self.icp_5a = Inception(in_channels=832, ch1x1=256, ch3x3red=160, ch3x3=320,
ch5x5red=32, ch5x5=128, pool_proj=128)
self.icp_5b = Inception(in_channels=832, ch1x1=384, ch3x3red=192, ch3x3=384,
ch5x5red=48, ch5x5=128, pool_proj=128)
self.avgpool5 = nn.AvgPool2d(kernel_size=7, stride=1, padding=0)
# 6
self.fc6 = nn.Linear(in_features=1024, out_features=1000)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2_red(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.icp_3a(x)
x = self.icp_3b(x)
x = self.maxpool3(x)
x = self.icp_4a(x)
x = self.icp_4b(x)
x = self.icp_4c(x)
x = self.icp_4d(x)
x = self.icp_4e(x)
x = self.maxpool4(x)
x = self.icp_5a(x)
x = self.icp_5b(x)
x = self.avgpool5(x)
x = x.view(x.size(0), -1)
x = self.fc6(x)
return x
def run_inception_naive():
BATCH_SIZE = 32
H, W = 100, 100
channels = 192
input_tensor = torch.randn(size=(BATCH_SIZE, channels, H, W))
inception = InceptionNaive(in_channels=192, ch1x1=64, ch3x3=128, ch5x5=32)
output_tensor = inception(input_tensor)
print(f"{output_tensor.shape=}")
def run_inception_dim_reduction():
BATCH_SIZE = 32
H, W = 100, 100
channels = 192
input_tensor = torch.randn(size=(BATCH_SIZE, channels, H, W))
# in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj
inception = Inception(in_channels=192, ch1x1=64,
ch3x3red=96,ch3x3=128,
ch5x5red=16, ch5x5=32,
pool_proj=32)
output_tensor = inception(input_tensor)
print(f"{output_tensor.shape=}")
def run_googlenet():
BATCH_SIZE = 32
H, W = 224, 224
channels = 3
input_tensor = torch.randn(size=(BATCH_SIZE, channels, H, W))
model = GoogLeNet(in_channels=channels)
pred = model(input_tensor)
print(f"{pred.shape=}")
if __name__ == '__main__':
# run_inception_naive()
# run_inception_dim_reduction()
run_googlenet()
CIFAR10 train full code
from dataclasses import dataclass
import torch.nn as nn
import torch
from torch.optim import Adam
from torchvision.datasets import CIFAR10
from torchvision.transforms import ToTensor
from chap3_deep_learning.dl_27_googlenet1 import Inception
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
from tqdm import tqdm
import csv
@dataclass
class Constants:
N_SAMPLES: int
BATCH_SIZE: int
EPOCHS: int
LR: float
DEVICE: torch.device
PATH: str
METRIC_PATH: str
SEED: int
def get_device():
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"curr device = {DEVICE}")
return DEVICE
def save_metrics(filepath, n_epochs, loss, accuracy):
epochs = [e for e in range(n_epochs)]
with open(filepath, mode='w', newline='') as file:
writer = csv.writer(file)
writer.writerow(['Epoch', 'Accuracy', 'Loss'])
for e, acc, l in zip(epochs, accuracy, loss):
writer.writerow([e, acc, l])
def visualize(losses, accrs):
fig, axes = plt.subplots(2, 1, figsize=(15, 7))
axes[0].plot(losses)
axes[1].plot(accrs)
axes[1].set_xlabel('EPOCHS', fontsize=15)
axes[0].set_ylabel('Loss', fontsize=15)
axes[1].set_ylabel('Accuracy', fontsize=15)
axes[0].tick_params(labelsize=15)
axes[1].tick_params(labelsize=15)
fig.suptitle("GoogLeNet Metrics by Epoch", fontsize=16)
plt.savefig('model/googlenet_vis.png')
plt.show()
class GoogLeNet(nn.Module):
def __init__(self, in_channels):
super(GoogLeNet, self).__init__()
# 1
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=64, kernel_size=7, padding=3, stride=2)
self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 2
self.conv2_red = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=1, padding=0, stride=1)
self.conv2 = nn.Conv2d(in_channels=64, out_channels=192, kernel_size=3, padding=1, stride=1)
self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 3
self.icp_3a = Inception(in_channels=192, ch1x1=64, ch3x3red=96, ch3x3=128,
ch5x5red=16, ch5x5=32, pool_proj=32)
self.icp_3b = Inception(in_channels=256, ch1x1=128, ch3x3red=128, ch3x3=192,
ch5x5red=32, ch5x5=96, pool_proj=64)
self.maxpool3 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 4
self.icp_4a = Inception(in_channels=480, ch1x1=192, ch3x3red=96, ch3x3=208,
ch5x5red=16, ch5x5=48, pool_proj=64)
self.icp_4b = Inception(in_channels=512, ch1x1=160, ch3x3red=112, ch3x3=224,
ch5x5red=24, ch5x5=64, pool_proj=64)
self.icp_4c = Inception(in_channels=512, ch1x1=128, ch3x3red=128, ch3x3=256,
ch5x5red=24, ch5x5=64, pool_proj=64)
self.icp_4d = Inception(in_channels=512, ch1x1=112, ch3x3red=144, ch3x3=288,
ch5x5red=32, ch5x5=64, pool_proj=64)
self.icp_4e = Inception(in_channels=528, ch1x1=256, ch3x3red=160, ch3x3=320,
ch5x5red=32, ch5x5=128, pool_proj=128)
self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 5
# self.icp_5a = Inception(in_channels=832, ch1x1=256, ch3x3red=160, ch3x3=320,
# ch5x5red=32, ch5x5=128, pool_proj=128)
# self.icp_5b = Inception(in_channels=832, ch1x1=384, ch3x3red=192, ch3x3=384,
# ch5x5red=48, ch5x5=128, pool_proj=128)
# self.avgpool5 = nn.AvgPool2d(kernel_size=7, stride=1, padding=0)
# 6
self.fc6 = nn.Linear(in_features=832, out_features=10)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2_red(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.icp_3a(x)
x = self.icp_3b(x)
x = self.maxpool3(x)
x = self.icp_4a(x)
x = self.icp_4b(x)
x = self.icp_4c(x)
x = self.icp_4d(x)
x = self.icp_4e(x)
x = self.maxpool4(x)
# x = self.icp_5a(x)
# x = self.icp_5b(x)
# x = self.avgpool5(x)
x = x.view(x.size(0), -1)
x = self.fc6(x)
return x
def train_cifar10(c):
data = CIFAR10(root='data', download=True, train=True, transform=ToTensor())
dataloader = DataLoader(data, batch_size=c.BATCH_SIZE, shuffle=True)
model = GoogLeNet(in_channels=3)
model = model.to(c.DEVICE)
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=c.LR)
losses, accs = list(), list()
for e in range(c.EPOCHS):
epoch_loss, n_corrects = 0., 0
for X_, y_ in tqdm(dataloader):
X_, y_ = X_.to(c.DEVICE), y_.to(c.DEVICE)
pred = model(X_)
optimizer.zero_grad()
loss = loss_fn(pred, y_)
loss.backward()
optimizer.step()
pred_cls = torch.argmax(pred, dim=1)
n_corrects += (pred_cls == y_).sum().item()
epoch_loss += loss
epoch_loss /= len(dataloader)
epoch_accr = n_corrects / c.N_SAMPLES
losses.append(epoch_loss.item())
accs.append(epoch_accr)
print(f"epoch {e}- loss: {epoch_loss.item():.4f}, accuracy: {epoch_accr:.4f}")
if e in [299, 499, 699, 899]:
torch.save(model, c.PATH.replace('.pt', f"_epoch_{e}.pt"))
save_metrics(filepath=c.METRIC_PATH, n_epochs=c.EPOCHS, loss=losses, accuracy=accs)
torch.save(model, c.PATH)
visualize(losses=losses, accrs=accs)
if __name__ == '__main__':
constants = Constants(
N_SAMPLES=50000,
BATCH_SIZE=2048,
EPOCHS=1000,
LR=0.0001,
DEVICE=get_device(),
PATH='model/googlenet_cifar10.pt',
METRIC_PATH='model/googlenet_cifar10_metric.csv',
SEED=80
)
train_cifar10(constants)

result
epoch 0- loss: 2.3027, accuracy: 0.1000
epoch 199- loss: 0.7501, accuracy: 0.7307
epoch 299- loss: 0.3771, accuracy: 0.8706
epoch 499- loss: 0.0636, accuracy: 0.9868
epoch 699- loss: 0.0367, accuracy: 0.9951
epoch 899- loss: 0.9127, accuracy: 0.6452
epoch 999- loss: 0.0140, accuracy: 0.9970
- 모델의 처음 시작은 10개 클래스에 대해 0.1의 정확도와, 2.3의 Crossentropy 오차로 시작
- 200 번 째 epoch 이후, accuracy와 loss가 꾸준히 개선되지 않고 변동폭이 점점 커지게 됨
- 결론적으로는 마지막 1000번째 epoch에서 정확도 0.99, loss 0.01으로 지표는 좋아보이지만
- overfitting되었을 수 도 있음 -> test data로 확인 하면 알 수 있음
- 중간 추출 모델 + 최종 모델을 evaluation해서 최종 모델을 선정하면 됨
'Education > 새싹 TIL' 카테고리의 다른 글
| 새싹 AI데이터엔지니어 핀테커스 13주차 (금) - ResNet Full & Early Stopping & Dropout & Batch Normalization (0) | 2023.12.01 |
|---|---|
| 새싹 AI데이터엔지니어 핀테커스 13주차 (목) - ResNet (0) | 2023.11.30 |
| 새싹 AI데이터엔지니어 핀테커스 13주차 (화) - VGGNet-11,13,19 & CIFAR10 (0) | 2023.11.28 |
| 새싹 AI데이터엔지니어 핀테커스 13주차 (월) - LeNet5 & VGGNet (1) | 2023.11.27 |
| 새싹 AI데이터엔지니어 핀테커스 12주차 (금) - Sobel Filtering 3 & Convolutional Neural Network (0) | 2023.11.24 |