728x90
2023-11-27 58th Class
Convolutional Neural Network - LeNet5
#️⃣ Train MNIST in LeNet5 Architecture
LeNet5는 3개의 Convolutional layer(C1, C3, C5)와 2개의 Pooling Layer(S2, S4) 그리고 Fully Connected Layer(F6, Output)의 구조를 가진 CNN 알고리즘
LeNet5의 구조

아래의 표를 참고하여 LeNet5 모델을 구현하고 MNIST 손글씨 데이터셋을 학습
| layer | Feature Map | Size | Kernel Size | Stride | Activation | |
|---|---|---|---|---|---|---|
| input | image | 1 | 32x32 | |||
| 1 | Convolution | 6 | 28x28 | 5x5 | 1 | tanh |
| 2 | Average Pooling | 6 | 14x14 | 2x2 | 2 | tanh |
| 3 | Convolution | 16 | 10x10 | 5x5 | 1 | tanh |
| 4 | Average Pooling | 16 | 5x5 | 2x2 | 2 | tanh |
| 5 | Convolution | 120 | 1x1 | 5x5 | 1 | tanh |
| 6 | FC | - | 84 | - | - | tanh |
| Output | FC | - | 10 | - | - | softmax |
[1] LeNet-5 Pytorch full code (To inspect intermediate values ver.)
import torch
import torch.nn as nn
import numpy as np
from torch.optim import Adam
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
from torch.utils.data import TensorDataset
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
from tqdm import tqdm
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.cnn1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2)
self.cnn1_act = nn.Tanh()
self.avgpool1 = nn.AvgPool2d(kernel_size=2, stride=2)
self.cnn2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5)
self.cnn2_act = nn.Tanh()
self.avgpool2 = nn.AvgPool2d(kernel_size=2, stride=2)
self.cnn3 = nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5)
self.cnn3_act = nn.Tanh()
self.fc1 = nn.Linear(in_features=120, out_features=84)
self.fc1_act = nn.Tanh()
self.fc2 = nn.Linear(in_features=84, out_features=10)
# self.out = nn.Softmax(dim=-1)
def forward(self, x):
x = self.cnn1(x)
x = self.cnn1_act(x)
x = self.avgpool1(x)
x = self.cnn2(x)
x = self.cnn2_act(x)
x = self.avgpool2(x)
x = self.cnn3(x)
x = self.cnn3_act(x)
x = x.view(x.size(0), -1)
x = self.fc1(x)
x = self.fc1_act(x)
x = self.fc2(x)
return x
def random_test_lenet():
model = LeNet()
# B, C, H, W
rand_test = torch.randn((10, 1, 28, 28))
rst = model(rand_test)
if rst.shape == (10, 10):
print("test passed")
def run_lenet():
# random test
# random_test_lenet()
# config
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# print(model)
EPOCHS = 3
LR = 0.001
BATCH_SIZE = 64
N_SAMPLES = 60000
# MNIST config
dataset = MNIST(root='data', train=True, download=True, transform=ToTensor())
dataloader = DataLoader(dataset, batch_size=BATCH_SIZE)
model = LeNet().to(DEVICE)
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=LR)
losses, accs = list(), list()
for e in range(EPOCHS):
epoch_loss, n_corrects = 0., 0
for X_, y_ in tqdm(dataloader):
X_, y_ = X_.to(DEVICE), y_.to(DEVICE)
pred = model(X_)
loss = loss_fn(pred, y_)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss += loss
pred_cls = torch.argmax(pred, dim=1)
n_corrects += (pred_cls == y_).sum().item()
epoch_loss /= N_SAMPLES
epoch_accr = n_corrects / N_SAMPLES
print(f"epoch {e} : loss={epoch_loss.item():.4f}, accr={epoch_accr}")
losses.append(epoch_loss)
accs.append(epoch_accr)
print(losses)
print(accs)
if __name__ == '__main__':
run_lenet()
100%|██████████| 938/938 [00:05<00:00, 174.04it/s]
epoch 0 : loss=0.0049, accr=0.9088166666666667
100%|██████████| 938/938 [00:03<00:00, 252.87it/s]
0%| | 0/938 [00:00<?, ?it/s]
epoch 1 : loss=0.0017, accr=0.9661833333333333
100%|██████████| 938/938 [00:03<00:00, 251.77it/s]
epoch 2 : loss=0.0011, accr=0.9784166666666667
[tensor(0.0011, device='cuda:0', grad_fn=<DivBackward0>)]
[0.9784166666666667]
Init
- Pytorch의 dataloader에는 (B, C, H, W) = (배치사이즈, 채널, 높이, 너비) 순으로 데이터가 들어감
- (64, 1, 28, 28)
- 64개의 데이터, 1개의 채널, 높이 28, 너비 28
- self.cnn1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2)
- 합성곱층(Convollutional Layer)으로 MNIST 데이터 (28x28)을 32x32 사이즈로 만든 후 연산을 하기위해 패딩을 2로 설정함
- 양쪽에 패딩 2씩 더하면 2+28+2 = 32가 되기 때문
- 결과: (64, 6, 28, 28)
- self.cnn1_act = nn.Tanh()
- Activation Function은 Sigmoid, ReLU, Tanh 다양하게 있음
- Lenet-5 모델에서는 하이퍼볼릭 탄젠트를 기본 활성화함수(activation function)로 사용
- 결과: (64, 6, 28, 28)
- 활성화 함수는 non-linear (비선형)을 더해주는 함수로 shape의 변화가 없음
- self.avgpool1 = nn.AvgPool2d(kernel_size=2, stride=2)
- Average Pooling은 커널 내의 모든 값의 평균을 구해 이미지를 축소시키는 것
- kernel_size는 stride와 같아야함
- 위의 예시에서는 커널2, 보폭2로 이미지의 크기가 2배 축소됨
- 결과: (64, 6, 14, 14)
forward
- x = x.view(x.size(0), -1)
- 특성 추출 레이어가 끝난후 Fully connected layer로 연결시키기 전 단계
- 이 상태에서는 Tensor의 shape이 (64, 120, 1, 1)임
- Fully Connected Layer에 연결하기 위해서는 기존의 4차원 텐서를 (64, 120)의 2차원 텐서로 변환해야함
- 따라서 첫번째 자리인 Batch Size는 그대로 사용하고, 나머지 두 번째, 세 번째, 네 번째 자리를 1개로 압축해야함
- x.view 함수에 (1,2)로 2차원을 만들고
- 첫 번째 자리의 값을 x.size(0) 혹은 x.shape[0]으로 설정하고, 나머지는 -1를 설정해서 나머지 값을 알아서 계산하게끔 함
- 이 경우 (64, 120, 1, 1)의 경우 (64, -1)로 설정하는 것과 같기 때문에
- (64, 120x1x1)로 계산이 됨
- 결과: (64, 120)
[2] LeNet-5 Pytorch full code (nn.Sequential ver.)
from collections import OrderedDict
import torch
import torch.nn as nn
from torch.optim import Adam
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
from tqdm import tqdm
## nn.Sequential로 변환
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.feature = nn.Sequential(OrderedDict([
('cnn1', nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2)),
('cnn1_act', nn.Tanh()),
('avgpool1', nn.AvgPool2d(kernel_size=2, stride=2)),
('cnn2', nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5)),
('cnn2_act', nn.Tanh()),
('avgpool2', nn.AvgPool2d(kernel_size=2, stride=2)),
('cnn3', nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5)),
('cnn3_act', nn.Tanh())
]))
self.classifier = nn.Sequential(OrderedDict([
('fc1', nn.Linear(in_features=120, out_features=84)),
('fc1_act', nn.Tanh()),
('fc2', nn.Linear(in_features=84, out_features=10))
]))
def forward(self, x):
x = self.feature(x)
x = x.view(x.shape[0], -1)
x = self.classifier(x)
return x
def run_lenet():
# config
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# print(model)
EPOCHS = 3
LR = 0.001
BATCH_SIZE = 64
N_SAMPLES = 60000
# MNIST config
dataset = MNIST(root='data', train=True, download=True, transform=ToTensor())
dataloader = DataLoader(dataset, batch_size=BATCH_SIZE)
model = LeNet().to(DEVICE)
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=LR)
losses, accs = list(), list()
for e in range(EPOCHS):
epoch_loss, n_corrects = 0., 0
for X_, y_ in tqdm(dataloader):
X_, y_ = X_.to(DEVICE), y_.to(DEVICE)
pred = model(X_)
loss = loss_fn(pred, y_)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss += loss
pred_cls = torch.argmax(pred, dim=1)
n_corrects += (pred_cls == y_).sum().item()
epoch_loss /= N_SAMPLES
epoch_accr = n_corrects / N_SAMPLES
print(f"epoch {e} : loss={epoch_loss.item():.4f}, accr={epoch_accr}")
losses.append(epoch_loss)
accs.append(epoch_accr)
print(losses)
print(accs)
if __name__ == '__main__':
run_lenet()
LeNet(
(feature): Sequential(
(cnn1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(cnn1_act): Tanh()
(avgpool1): AvgPool2d(kernel_size=2, stride=2, padding=0)
(cnn2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(cnn2_act): Tanh()
(avgpool2): AvgPool2d(kernel_size=2, stride=2, padding=0)
(cnn3): Conv2d(16, 120, kernel_size=(5, 5), stride=(1, 1))
(cnn3_act): Tanh()
)
(classifier): Sequential(
(fc1): Linear(in_features=120, out_features=84, bias=True)
(fc1_act): Tanh()
(fc2): Linear(in_features=84, out_features=10, bias=True)
)
)
100%|██████████| 938/938 [00:04<00:00, 212.41it/s]
epoch 0 : loss=0.0052, accr=0.9029333333333334
100%|██████████| 938/938 [00:04<00:00, 211.73it/s]
0%| | 0/938 [00:00<?, ?it/s]
epoch 1 : loss=0.0017, accr=0.9664833333333334
100%|██████████| 938/938 [00:05<00:00, 173.63it/s]
epoch 2 : loss=0.0011, accr=0.9776833333333333
[tensor(0.0011, device='cuda:0', grad_fn=<DivBackward0>)]
[0.9776833333333333]
- Sequential Class를 사용하면 아래의 2가지 방법이 있음
- 1번: 레이어 이름 없이 바로 작성
- 2번: 레이어에 이름을 붙이고 Collections 모듈의 OrderedDict를 사용해 순서가 있는 Dictionary 형태로작성
- Sequential — PyTorch 2.1 documentation
예시
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
# Using Sequential with OrderedDict. This is functionally the
# same as the above code
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))
VGGNET
#️⃣ VGGNET
VGGNet은 이미지처리에 유리한 모델 중 하나임
1000개의 클래스로 이루어진 이미지 분류 대회의 (ILSVRC) 여러 모델의 퍼포먼스 (표)
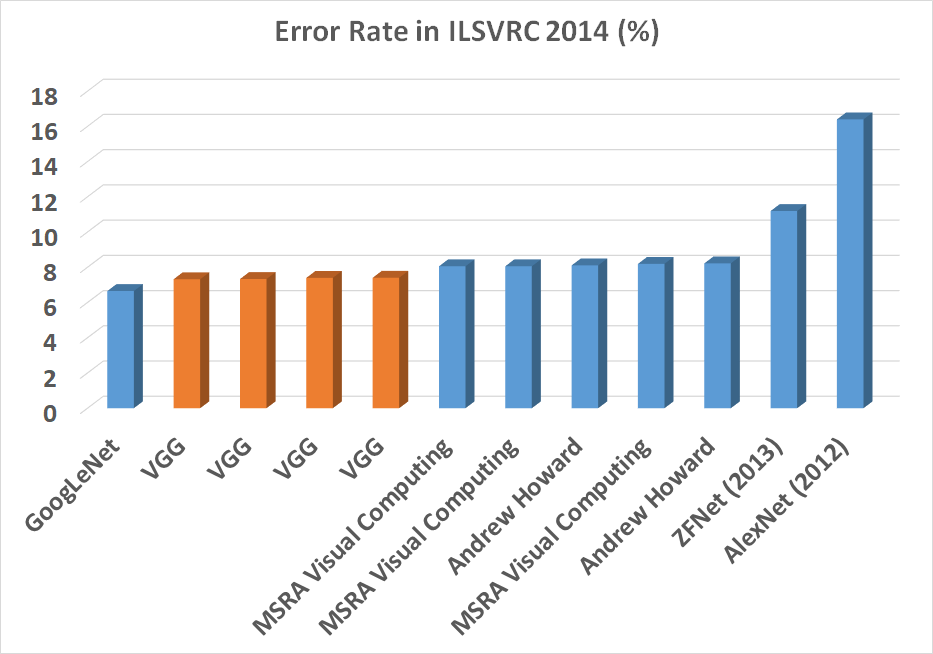
- VGG Model은 GoogLeNet보다 우수한 성능을 보여줌
- ZFNet (2013)은 XAI에 중요한 모델
- VGG는 Object Detection할 때 Backbone Network로 많이 사용됨
- (Feature Extraction을 VGG가 많이 함)
VGG 아키텍처
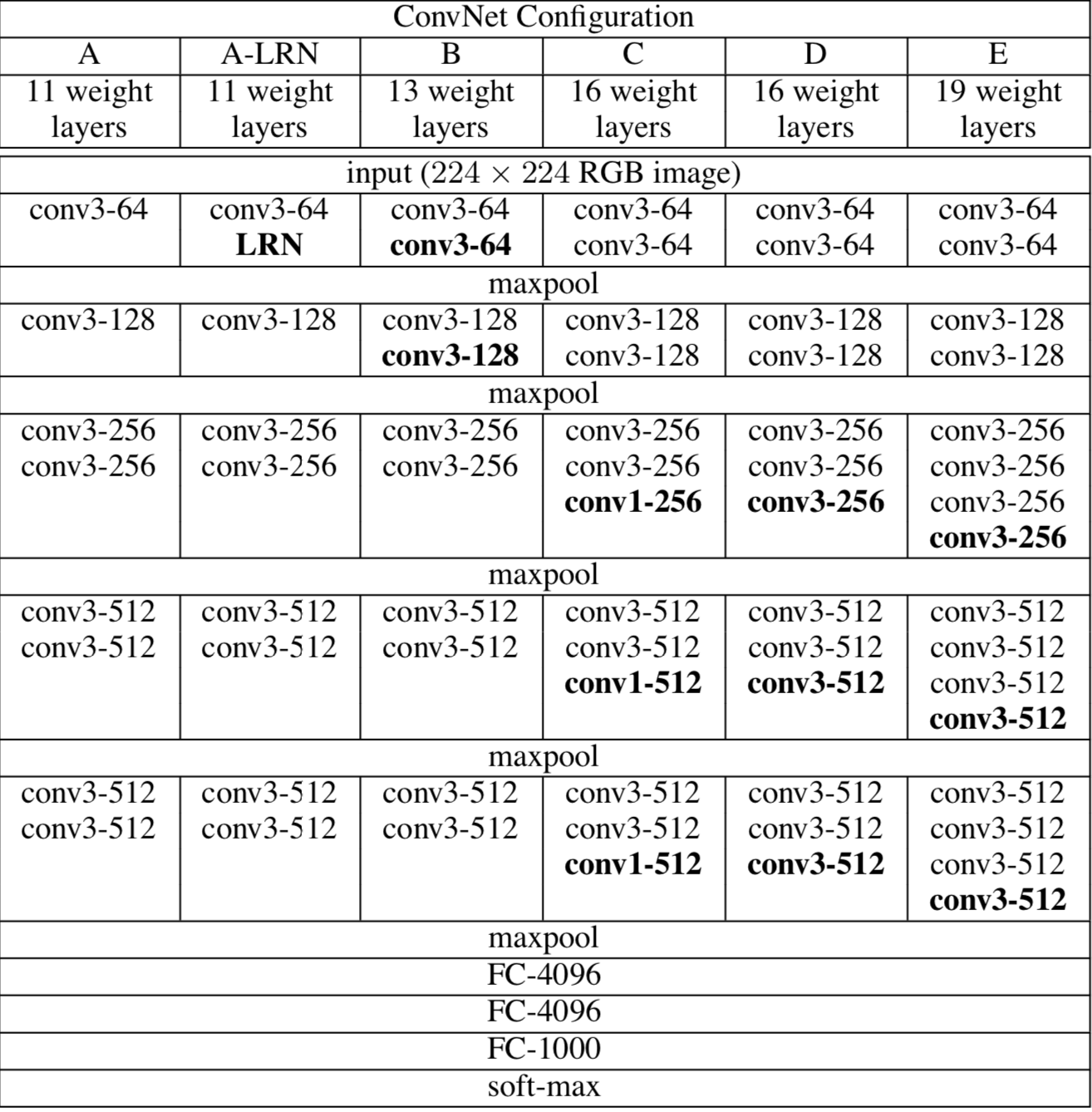
- 초기에는 Depth를 늘리면서 gradient vanishing problem을 낮추는 것에 목표를 둔 모델이 많이 등장
- depth를 늘리는 것은 복잡한 합성함수가 되면서, 복잡한 패턴을 추출할 수 있다는 것을 의미함
- 논문에 따르면 LRN은 의미 없다고 함
- VGG는 A, A-LRN, B로 부르지 않고 weight 개수인 VGG-11, VGG-13, VGG-16… 으로 부름
- 11개의 weight을 가진 layers는 convolutional layer 8개 + fully connected layer 3개 = 11개라는 의미
- Conv2D + ReLu + Pool 을 통과하면 이미지 사이즈는 절반으로 줄어들게 됨
- VGGNet에서는 이미지 사이즈가 줄어들기 전에 복잡도를 추가하는 방법으로 CRCR Pooling 을 사용함
- CRCR Pooling = Convolutional > ReLu > Convolutional > ReLU > Pool 방식으로 합성곱과 활성화함수를 풀링 이전에 추가하여 모델의 복잡도를 더함
- Kernel Size=3, padding=1, stride=1일 때 이미지사이즈가 유지되기 때문에 VGGNet의 Convolutional Layer의 파라미터에는 이 설정을 기본으로 함
- 그렇게 했을 때, 이미지 사이즈는 유지하면서 복잡도를 더해주게 되는 것임
#️⃣ VGG11 Pytorch로 구현하기
- Input Image Size는 (224, 224, 3)
- Pooling Layer는 nn.MaxPool2D 이용
code
import torch
import torch.nn as nn
from collections import OrderedDict
import numpy as np
from torch.utils.data import DataLoader
class VGGNet(nn.Module):
def __init__(self):
super(VGGNet, self).__init__()
self.feature = nn.Sequential(OrderedDict([
# 1. input (224 x 224x RGB image)
('conv3-64', nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, padding=1)),
('conv3-64-act', nn.ReLU()),
('maxpool1', nn.MaxPool2d(kernel_size=2, stride=2)),
# 2.
('conv3-128', nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=1)),
('conv3-128-act', nn.ReLU()),
('maxpool2', nn.MaxPool2d(kernel_size=2, stride=2)),
# 3.
('conv3-256-1', nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, padding=1)),
('conv3-256-1-act', nn.ReLU()),
('conv3-256-2', nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, padding=1)),
('conv3-256-2-act', nn.ReLU()),
('maxpool3', nn.MaxPool2d(kernel_size=2, stride=2)),
# 4.
('conv3-512-1', nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, padding=1)),
('conv3-512-1-act', nn.ReLU()),
('conv3-512-2', nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1)),
('conv3-512-2-act', nn.ReLU()),
('maxpool4', nn.MaxPool2d(kernel_size=2, stride=2)),
# 5.
('conv3-512-3', nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1)),
('conv3-512-3-act', nn.ReLU()),
('conv3-512-4', nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1)),
('conv3-512-4-act', nn.ReLU()),
('maxpool5', nn.MaxPool2d(kernel_size=2, stride=2))
]))
# (Batch ,C , h W) -> (Batch , x)
self.classifier = nn.Sequential(OrderedDict([
('fc-4096-1', nn.Linear(in_features=512*7*7, out_features=4096)),
('fc-4096-1-act', nn.ReLU()),
('fc-4096-2', nn.Linear(in_features=4096, out_features=4096)),
('fc-4096-2-act', nn.ReLU()),
('fc-1000', nn.Linear(in_features=4096, out_features=1000)),
]))
# 64, 512, 7, 7
# (64, b)
def forward(self, x):
x = self.feature(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
def run_vggnet():
test_data = torch.randn((10, 3, 224, 224))
model = VGGNet()
print(model)
pred = model.forward(test_data)
print(pred.shape)
if __name__ == '__main__':
run_vggnet()
VGGNet(
(feature): Sequential(
(conv3-64): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv3-64-act): ReLU()
(maxpool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv3-128): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv3-128-act): ReLU()
(maxpool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv3-256-1): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv3-256-1-act): ReLU()
(conv3-256-2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv3-256-2-act): ReLU()
(maxpool3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv3-512-1): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv3-512-1-act): ReLU()
(conv3-512-2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv3-512-2-act): ReLU()
(maxpool4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv3-512-3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv3-512-3-act): ReLU()
(conv3-512-4): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv3-512-4-act): ReLU()
(maxpool5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(fc-4096-1): Linear(in_features=25088, out_features=4096, bias=True)
(fc-4096-1-act): ReLU()
(fc-4096-2): Linear(in_features=4096, out_features=4096, bias=True)
(fc-4096-2-act): ReLU()
(fc-1000): Linear(in_features=4096, out_features=1000, bias=True)
)
)
torch.Size([10, 1000])
- self.feature: 특징 추출 레이어로 Convolutional Layer를 여러개 쌓아 복잡한 특징을 추출하는 구간
- 모든 구간에 kernel은 3, padding은 1로 이렇게 계산할 시
- H’ = H + 2P - F + 1
- H’ = H + 2 - 3 +1 -> H’ = H
- 가 되어서 합성곱층 이후 이미지의 사이즈 변화 없이 동일한 크기의 output이 나오게 됨
- 즉 이미지가 줄어들지 않고 더 복잡한 convolutional layer(특성추출 구간)을 추가하여
- 모델의 복잡도를 높히고, 다양한 패턴을 추출할 수 있도록 함
- self.classifier: 분류 레이어로 fully connected layer를 통해 추출된 특징을 가지고 데이터를 분류하는 구간
- (‘fc-4096-1’, nn.Linear(in_features=512*7*7, out_features=4096)),
- 이 구간에서 512x7x7이 되는 부분에 대해서 학원 친구들이 나에게 많이 물어보았음
- VGG-NET에서 모든 구간에서 이미지사이즈는 동일하고, 224x224
- 채널의 수만 output size로 변경이 됨
- 그리고 MaxPooling 구간에서 kernel=2, stride=2로 크기가 절반씩 줄어들기 때문에
- 결론적으로는 maxpooling의 개수인 5개만 계산해서 224에 나누어 주면 됨
- 224 / 2^5 = 224/32 = 7, => 7x7
- 따라서 FC층 직전의 shape는 (B, C, H, W) = (10, 512, 7, 7) 이 되고
- 4차원을 FC층에 옮기기 위해 Batch Size를 제외하고 Flatten 하면
- (10, 512x7x7) = (10, 25088)이 됨
- 이하는 Le-Net5와 동일함
반응형
'Education > 새싹 TIL' 카테고리의 다른 글
| 새싹 AI데이터엔지니어 핀테커스 13주차 (수) - GoogLeNet (0) | 2023.11.29 |
|---|---|
| 새싹 AI데이터엔지니어 핀테커스 13주차 (화) - VGGNet-11,13,19 & CIFAR10 (0) | 2023.11.28 |
| 새싹 AI데이터엔지니어 핀테커스 12주차 (금) - Sobel Filtering 3 & Convolutional Neural Network (0) | 2023.11.24 |
| 새싹 AI데이터엔지니어 핀테커스 12주차 (목) - Sobel Filtering 2 (3) | 2023.11.23 |
| 새싹 AI데이터엔지니어 핀테커스 12주차 (수) - Sobel Filtering (2) | 2023.11.22 |