2023-12-01 62th Class
Convolutional Neural Network - ResNet Full
#️⃣ ResNet Full Code
Overfitting
#️⃣ Scheduler
scheduler란 optimizer을 대상으로 학습을 진행하면서 learning rate를 조정하도록 하는 것
epoch마다 learning rate가 줄어들게 됨
Pytorch에서는 scheduler.step()을 통해 실행
#️⃣ Overfitting
noise를 적당히 반영하여 일반화한 함수를 학습하는 것이 이상적인 모델
noise를 지나치게 학습하여 일반화한 함수에서 벗어나면 loss는 낮지만 실제 성능은 떨어지는 모델
이 noise까지 학습한 상태를 overfitting(과적합)라고 부름
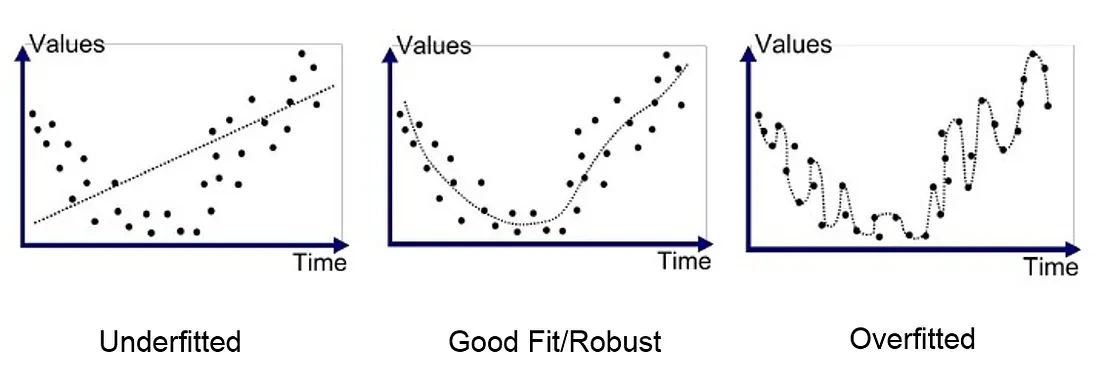
- 맨 오른쪽 Overfitted model은 training 데이터에는 잘 적합되었지만
- general data를 예측할 때는 정확도가 떨어지는 문제가 발생함
loss가 줄어도, overfitting이 발생할 수 있음
따라서 언제 overfitting이 발생하는 지 확인하는 방법이 필요
#️⃣ How to Detect Overfitting
모델을 학습하는 과정에서 train data중 일부를 학습에 참여하지 않도록 분리를 하고
그 분리한 데이터(unseen data)로 성능을 측정하여 과적합 여부를 판단
이 unseen data를 validation data라고 부름
Validation Data
일반적으로 학습 데이터의 내부 분할 비율은 아래와 같음
train set: validation dataset = 8:2
- overfitting은 validation data의 loss가 증가하기 시작하는 지점부터 발생함
- 위의 그림은 sweet spot부터 over fitting이 시작됨
- pytorch에서 데이터셋의 분리는 n_train_samples = int(TRAIN_VAL_RATIO * n_total_samples)로 실행
validation의 dataloader batch size는 메모리가 허용하는 한 가장 큰 사이즈로 설정 (N_SAMPLES)
Early Stopping
#️⃣ 모델 학습 조기 종료
일반적으로 validation loss는 감소하다가 일시적으로 증가하는 fluctuation 현상이 발생함
따라서 오차가 증가한다고 바로 모델 학습을 중단시키는 것이 아닌, patience (기다리는 횟수)를 적용하여
patience 임계치를 넘어가는 시점에 early stopping을 하게 됨
Dropout
#️⃣ 드롭아웃
등장 배경
초기 세팅되는 뉴런의 파라미터가 같다면 학습되는 내용이 비슷하게 되어
그 Neural Network가 비효율적일 수 밖에 없음
정의
드롭아웃이란 iteration 마다 일정 확률로 neuron을 deactivate 하는 방법
비슷한 neuron이 만들어지는 것을 막는 기법임
dropout은 train phase에서만 사용하는 것으로
test process에서는 모든 뉴런을 activation 시킨 상태에서 inference 해야함
pytorch에서는 dropout = nn.Dropout(p=0.5)로 드롭아웃을 시킴
- dropout.train()일때는 드롭아웃이 실행됨
- 뉴런의 값이 0으로 변경됨
- dropout.eval()일때는 드롭아웃이 실행되지 않음
- 0이었던 뉴런의 값이 되살아남
dropout은 주로 fully-connected layers 사이에 사용
사용할 것이면 fully-connected layer 사이사이에 모두 사용해야하고,
마지막 fully connected layer 에서는 최종 features 개수로 출력되기 때문에 dropout을 사용하면 안됨
Batch Norms
#️⃣ 배치 정규화
mean subtraction ->
배치정규화를 해주는 이유=Covariate Shift
데이터가 레이어를 통과할 때마다 데이터의 분포가 바뀌기 때문에
학습의 비효율성을 야기할 수 있음
따라서 배치 정규화를 통해 데이터 분포를 가운데로 이동시켜줌
batch norm은 주로 convolutional layer 뒤에 사용함
CBR (Convolutional > Batch > ReLU)

- 검은 점선 -> GoogLeNet이 0.5 > 0.7로 상승
- 실제로는 15~20% 정도 올라가는 효과
- 일반적으로 batch norms는 dropout에 비해 성능 개선 효과가 우수함
2015년 이후 internal covariate shift를 해결하기 위해 batch normalization을 많이 사용하게 됨
하지만 이후 MIT에서는 batch normalization이 성능을 올려주는것은 맞지만
internal covariate shift를 해결해서 성능을 올린것이 아니라는 논문을 발표하였음
'Education > 새싹 TIL' 카테고리의 다른 글
| 새싹 AI데이터엔지니어 핀테커스 14주차 (화) - PJT 2 Transformer Study (1) | 2023.12.05 |
|---|---|
| 새싹 AI데이터엔지니어 핀테커스 14주차 (월) - PJT 1 Research (1) | 2023.12.05 |
| 새싹 AI데이터엔지니어 핀테커스 13주차 (목) - ResNet (0) | 2023.11.30 |
| 새싹 AI데이터엔지니어 핀테커스 13주차 (수) - GoogLeNet (1) | 2023.11.29 |
| 새싹 AI데이터엔지니어 핀테커스 13주차 (화) - VGGNet-11,13,19 & CIFAR10 (1) | 2023.11.28 |