728x90
2023-10-31 39th Class
AutoML 머신러닝 모델 선정
#️⃣ AutoML 라이브러리인 Pycaret과 Autogluon 사용하여 모델 테스트
| Model | Accuracy | AUC | Recall | Prec. | F1 | Kappa | MCC | |
|---|---|---|---|---|---|---|---|---|
| lightgbm | Light Gradient Boosting Machine | 0.9701 | 0.9926 | 0.8833 | 0.9277 | 0.9045 | 0.8868 | 0.9926 |
| gbc | Gradient Boosting Classifier | 0.9643 | 0.9881 | 0.8333 | 0.938 | 0.8822 | 0.8612 | 0.9881 |
| rf | Random Forest Classifier | 0.9577 | 0.9873 | 0.7999 | 0.9277 | 0.8588 | 0.8341 | 0.9873 |
| ada | AdaBoost Classifier | 0.954 | 0.9829 | 0.8131 | 0.8923 | 0.8502 | 0.8231 | 0.9829 |
| et | Extra Trees Classifier | 0.9372 | 0.9796 | 0.6603 | 0.9286 | 0.771 | 0.7359 | 0.9796 |
| dt | Decision Tree Classifier | 0.931 | 0.8652 | 0.7683 | 0.7963 | 0.781 | 0.7402 | 0.8652 |
| lr | Logistic Regression | 0.9015 | 0.9164 | 0.5286 | 0.7909 | 0.6327 | 0.5785 | 0.9164 |
| lda | Linear Discriminant Analysis | 0.9 | 0.9187 | 0.5891 | 0.7375 | 0.6542 | 0.5966 | 0.9187 |
- AutoML 라이브러리인 Pycaret과 Autogluon을 사용하여 베이스 모델로 사용할 모델을 탐색
- 기본 데이터 셋 테스트로 성능이 우수한 모델중 ensemble 및 트리모델 계열 5가지를 선정 후 모델 학습을 진행하였음.
모델 성능 비교 Confusion matrix
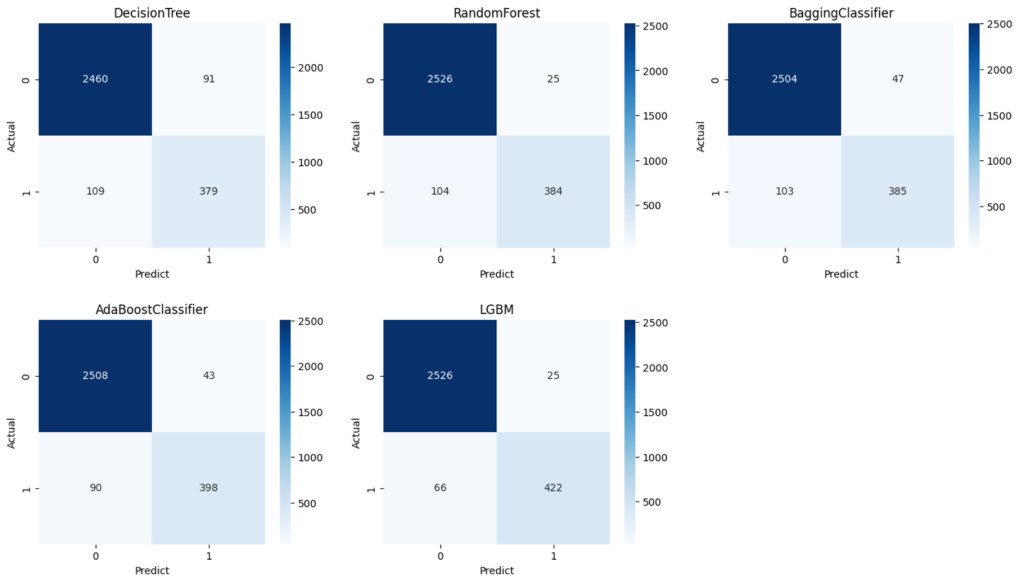
#️⃣ 1차 모델 성능비교 : 하이퍼 파라미터 조정 전
- 5가지 모델 선정 및 학습
- DecisionTree, RandomForest, BaggingClassifier, AdaBoost, LightGBM
- 모델의 Confusion Matrix 시각화
- Accuray, Precision, Rcall, F1값을 도출
#️⃣ Confusion Matrix 의미
-
TP : 유지 고객, 프로모션 미대상
-
FN : 유지 고객, 프로모션 대상
-
FP : 이탈 고객, 프로모션 미대상
-
TN : 이탈 고객, 프로모션 대상
-
머신러닝 모델은 Decision Tree, RandomForest, BaggingClassifier,AdaBoost, LightGBM 총 5가지를 선택해 비교해보았음.
-
그중 LGBM의 성능이 가장 우수
성능 지표 기준 Recall
**
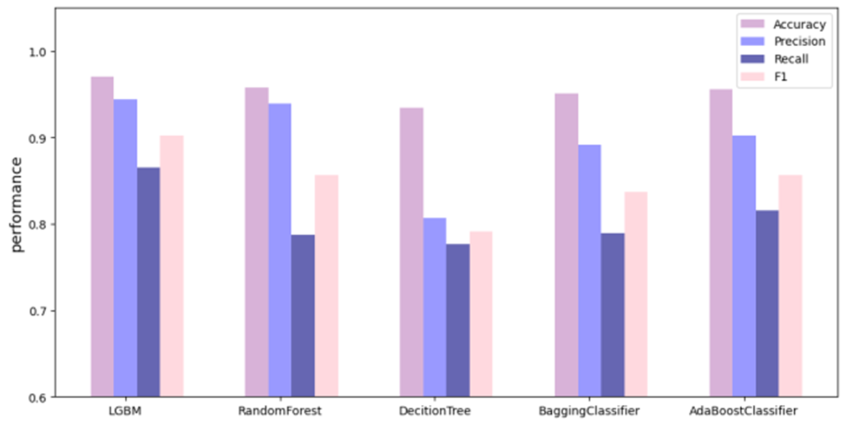
#️⃣ 성능 지표 의미
-
Accuray: 유지/이탈 고객 예측 비율
-
Precision: 유지 예측 고객의 유지 고객 비율
-
Recall: 유지 고객의 유지 예측 고객 비율
-
F1: Precision과 Recall의 조화 평균 성능 (종합적인 수치)
-
팀에서 설정한 비즈니스 목표는 프로모션 낭비를 최소화하여 충성고객을 확보하는 것
-
FN 만큼 프로모션 비용이 낭비되므로,
-
FN 최소화를 위해 재현율(recall)을 가장 주요한 성능 지표로 선택함
모델 선택 LightGBM
#️⃣ LightGBM의 아이디어 1. 앙상블 학습 방식
Random Forest
- 독립적인 결정 트리를 독립(병렬)적으로 학습
- 각 트리는 부스트스트랩 샘플링과 랜덤특성 선택을 통해 다양성을 확보
Gradient Boosting - 결정 트리를 순차적으로 학습
- 이전 트리의 오류를 보완하여 새로운 모델을 반복적으로 학습
#️⃣ LightGBM의 아이디어 2. 오류보완의 방식
- 가중치 부여 방식 : 오분류된 샘플에 높은 가중치를 부여하여 높은 가중치를 가진 샘플에 집중
- Adaboost
- 손실함수 방식 : 실제값과 예측값의 차이(손실)를 훈련데이터에 투입하고 경사하강법과 같은 최적화 기술을 이용하여 모델을 개선
- Gradient Boosting Methods: XGBoost, LightGBM, Catboost
#️⃣ LightGBM의 아이디어 3. 트리 분할의 방식
- GBM 계열 : ‘균형 트리 분할(level-wise)’ 방식을 사용
- 트리의 깊이가 균형적
- 각 노드 분할 고려하여 비효율적인 계산
- LightGBM : 최대 정보획득(Information Gain) 가지는 노드를 중심으로 계속해서 분할하는 ‘리프 중심 트리 분할(leaf-wise)’ 방식을 사용
- 과적합 최소화
- 높은 예측 성능
- 효율적인 계산
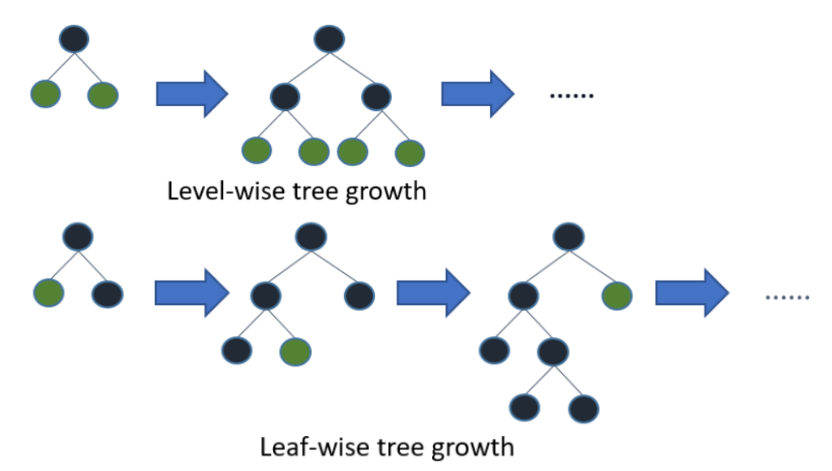
- LightGBM은 앙상블 학습 방식으로 랜덤포레스트를 베이스로 이용
- 그리고 학습진행은 손실함수 방식인 Gradient Boosting 기법으로 이전 트리의 오류를 보완하여 새로운 모델을 반복적으로 학습
- LightGBM의 트리분할은 leaf-wise 방식을 사용하여 과적합을 최소화하고, 성능이 좋고, 효율적으로 계산
하이퍼파라미터 최적화
#️⃣ Pycaret
- AutoML 중 Pycaret을 이용하여 hyperparameter 최적화
- 모델성능 검증 및 최적의 파라미터 확인
#️⃣ Randomized Search
- 무작위 샘플링 : 하이퍼파라미터 조합을 고려하지 않고 무작위로 조합
- 확률 분포 : 각 하이퍼파라미터에 대해 가능한 값들을 지정된 확률 분포에서 무작위로 추출
#️⃣ 모델의 성능 개선
- 성능 지표 Accuracy, Precision, Recall, F1 값 모두
최적화 이전보다 개선되었음
Accuracy :0.9210
Precision :0.9399
Recall :0.8975
F1 :0.9182
**
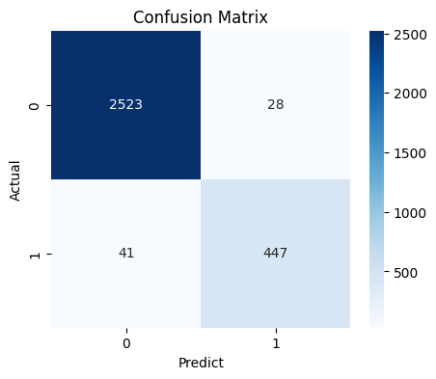
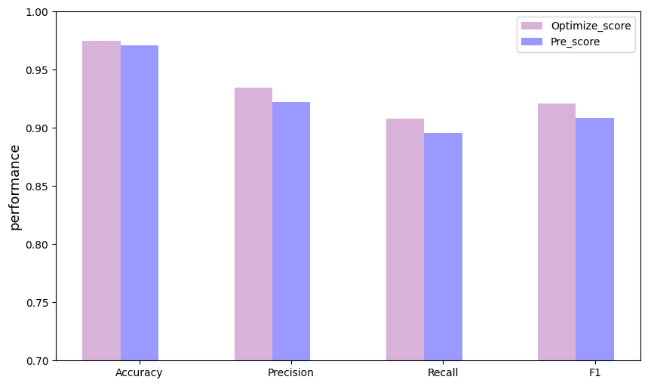
- 하이퍼 파라미터 최적화는 1차로 Pycaret을 통해 진행하였음.
- 그 후 Randomized Search로 추가 최적화를 한 결과 모델의 성능이 전반적으로 개선되었음.
반응형
'Education > 새싹 TIL' 카테고리의 다른 글
| 새싹 AI데이터엔지니어 핀테커스 9주차 (목) - PJT 4 Segment Analysis (0) | 2023.11.02 |
|---|---|
| 새싹 AI데이터엔지니어 핀테커스 9주차 (수) - PJT 3 Customer Clustering via K-means and LGBM (0) | 2023.11.01 |
| 새싹 AI데이터엔지니어 핀테커스 9주차 (월) - PJT 1 EDA & Data Preprocessing (0) | 2023.10.30 |
| 새싹 AI데이터엔지니어 핀테커스 8주차 (금) - PJT Preliminaries (InsureTech) (0) | 2023.10.27 |
| 새싹 AI데이터엔지니어 핀테커스 8주차 (목) - PJT Preliminaries (RA, Bank & Insurance) (1) | 2023.10.26 |