2023-11-01 40th Class
최적 LightGBM 모델의 Predict Proba와 Feature Importance
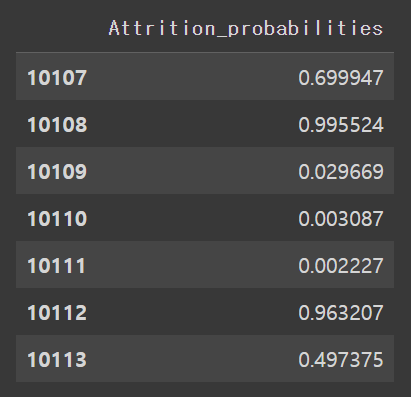
#️⃣ Predict Probability : 예측 확률
- 최적화된 LGBM모델로 모든 고객의 이탈 확률을 도출
- 이탈, 유지고객 이분적으로 예측하는 것이 아니라,
이탈 고객이 될 확률을 0~1 사이값으로 구한 것
class_probabilities = random_search.predict_porba(data.drop([“Attrition_Flag”], axis=1))
df_proba=pd.DataFrame(class_probabilies[:, 1], columns=[“Attrition_probabilites”]
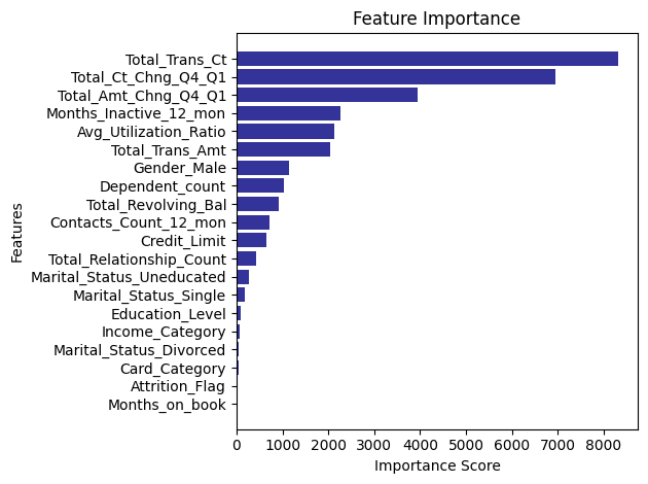
#️⃣ Feature Importance : 중요 변수
- 최적화된 LGBM모델로 이탈고객을 예측하는데 중요한 Features를 판별
- Importance Score 높으면 예측에 높은 비율로 반영 됨
- LightGBM은 임계치를 기준으로 최종 y값을 분류하므로, 이때 나오는 Predict Proba를 이탈 가능성으로 간주할 수 있음
- 이 Predict Proba는 0에서 1사이에 분포하게 되고
- Features Importance를통해 분류 결과에 가장 중요한 영향을 미치는 피처 확인 가능
이탈 고객 예측 모델을 타겟 마케팅에 활용하는 방안
이탈 고객을 예측하는 모델을 완성한 뒤,
이탈모델을 활용하여 이탈고객 예측 이외의
비즈니스 인사이트를 도출할 수 있는 방법에 대해 고민하였음
기존 고객을 유지하는 비용은 새로운 고객을 확보하는 비용보다 저렴하다. 신규 고객 한 명을 확보하는 것은 기존 고객 유지의 5~25배 비용이 들고(Harvard Business Review), 충성도가 높은 8%의 고객은 전체 매출의 40%를 차지한다.
상기 내용에 따라 우리 팀의 마케팅 전략은 최소 투자로 최대 이익 달성을 위해
이하의 2가지를 중점으로 수립하였음
- 마케팅 집행 비용의 낭비를 최소화 할 것
- 이탈 고객이 아닌 유지고객의 리텐션을 위한 마케팅을 집행할 것
리텐션 마케팅의 타겟 세그먼트를 선정하는 방법에 대하여
현재는 유지고객이지만 이탈 위기에 놓인 고객을 타겟팅해
이탈을 방지하는 것이 가장 적합하다고 판단하였음
따라서 아래와 같은 가설을 세움
#️⃣ 가설
모델이 예측한 이탈 확률과 주요 지표를 통해
유지 고객이지만 이탈 가능성이 높은 고객을 찾을 수 있을 것이다.
- LGBM predict proba와, feature importance를 활용해 고객을 클러스터링하여 상세분석 진행
전략 수립 프로세스
- 고객 이탈 예측 모델의 이탈 예측값으로 그룹화
- 유지고객 중 이탈 가능성이 매우 높은 고객군 도출
- 고객군 분석 및 마케팅 전략 수립
최적의 군집화 특성 도출
고정 특성 (fixed feature)
- 이탈 예측 : Attrition_probabilities(Predict_Proba)
제외 특성 (excluded features)
- 명목변수 (Nominal Variable)
최적의 군집화를 위한 특성 조합 후보 상위 4개
- 3개의 features 조합과 4개 이하의 클러스터 조건
- 모든 조합의 kmeans Clustering Silhouette 기준 상위 4개 후보군 도출
- Total_Ct_Chng_Q4_Q1, Total_Trans_Amt, Attrition_probabilities (3)
- Total_Amt_Chng_Q4_Q1, Total_Trans_Amt, Attrition_probabilities (3)
- Total_Trans_Ct, Total_Trans_Amt, Attrition_probabilities (3)
- Total_Ct_Chng_Q4_Q1, Avg_Utilization_Ratio, Attrition_probabilities (3)
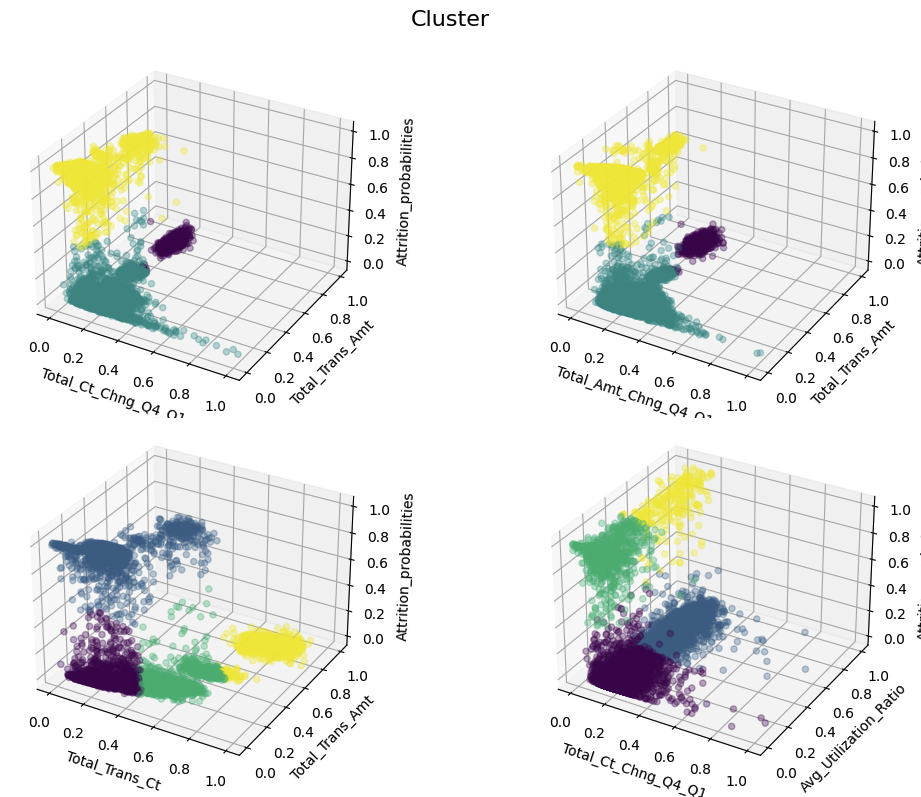
실루엣 스코어가 가장 높은 4개 기준으로 좌측 상단의 클러스터링 결과를 고객 세그먼트 분석에 사용하기로 함
=> 최종 축으로 사용된 피처는 1분기 대비 4분기 거래건수 비율과 12개월 동안의 총 거래금액
이유
- y축인 attrition_probabilities는 고객 이탈 가능성으로 이탈 확률이 높은(~1) 노란색 클러스터와 이탈 확률이 낮은(0~) 초록색, 보라색 클러스터로 비교적 양분화되어있음
- 즉 이탈고객과 유지고객이 뚜렷하게 나누어져있어 유지고객과 이탈 고객의 분리가 잘 되어있음
- 이탈 고객군으로 볼 수 있는 노란색 클러스터는 이탈고객 1587명과 유지 고객 40명으로 0.09의 낮은 entropy로 불순도가 낮음
- 노랑 세그먼트내 40명의 유지고객은 이탈 확률이 매우 높은 고객
- 나머지 초록, 보라 클러스터중, 보라색은 적은수 & 거래금액이 높고 응집도가 높아 가장 특징이 뚜렷한 고객군이고 이상적 고객군으로 추정
- 초록색 클러스터는 비교적 넓게 분포하여서 general한 고객군으로 추정
import numpy as np
entropy = -((40/1627) * np.log2(40/1627)) + ((1587/1627) * np.log2(1587/1627))
print(f"{entropy=:.4f}")
# entropy=0.0964
따라서 노랑 고객(attrited), 초록 고객(general 추정), 보라 고객(loyal customer 추정)의 세부 분석을 통해
타겟 마케팅 방법 및 리텐션 대응 전략의 세부 내용을 수립하기로 함
'Education > 새싹 TIL' 카테고리의 다른 글
| 새싹 AI데이터엔지니어 핀테커스 9주차 (금) - PJT 5 Marketing Strategy (0) | 2023.11.03 |
|---|---|
| 새싹 AI데이터엔지니어 핀테커스 9주차 (목) - PJT 4 Segment Analysis (0) | 2023.11.02 |
| 새싹 AI데이터엔지니어 핀테커스 9주차 (화) - PJT 2 ML Modeling & Model Tuning (1) | 2023.10.31 |
| 새싹 AI데이터엔지니어 핀테커스 9주차 (월) - PJT 1 EDA & Data Preprocessing (2) | 2023.10.30 |
| 새싹 AI데이터엔지니어 핀테커스 8주차 (금) - PJT Preliminaries (InsureTech) (0) | 2023.10.27 |