❤️ 배운 것
개인별 violinplot, pairplot 알고리즘 작성
Iris dataset
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
def get_iris():
iris = load_iris()
for attr in dir(iris):
print(attr)
# DESCR
# data # data_module # feature_names # filename # frame # target # target_names
# 대문자는 행렬, 소문자는 벡터
iris_X = iris.data
iris_y = iris.target
feature_names = iris.feature_names
species = iris.target_names
n_feature = len(feature_names)
n_species = len(species)
return iris_X, iris_y, feature_names, species, n_feature, n_species품종별 feature violinplot
def iris_visualization1():
iris_X, iris_y, feature_names, species, n_feature, n_species = get_iris()
cls_0 = iris_X[iris_y == 0]
cls_1 = iris_X[iris_y == 1]
cls_2 = iris_X[iris_y == 2]
xticks = np.arange(3)
fig, axes = plt.subplots(2, 2, figsize=(14, 14))
for i, ax in enumerate(axes.flat):
ax.violinplot([cls_0[:, i], cls_1[:, i], cls_2[:, i]],
positions=xticks)
ax.set_xticks(xticks)
ax.set_xticklabels(species)
ax.set_title(feature_names[i], fontsize=20)
ax.tick_params(labelsize=20)
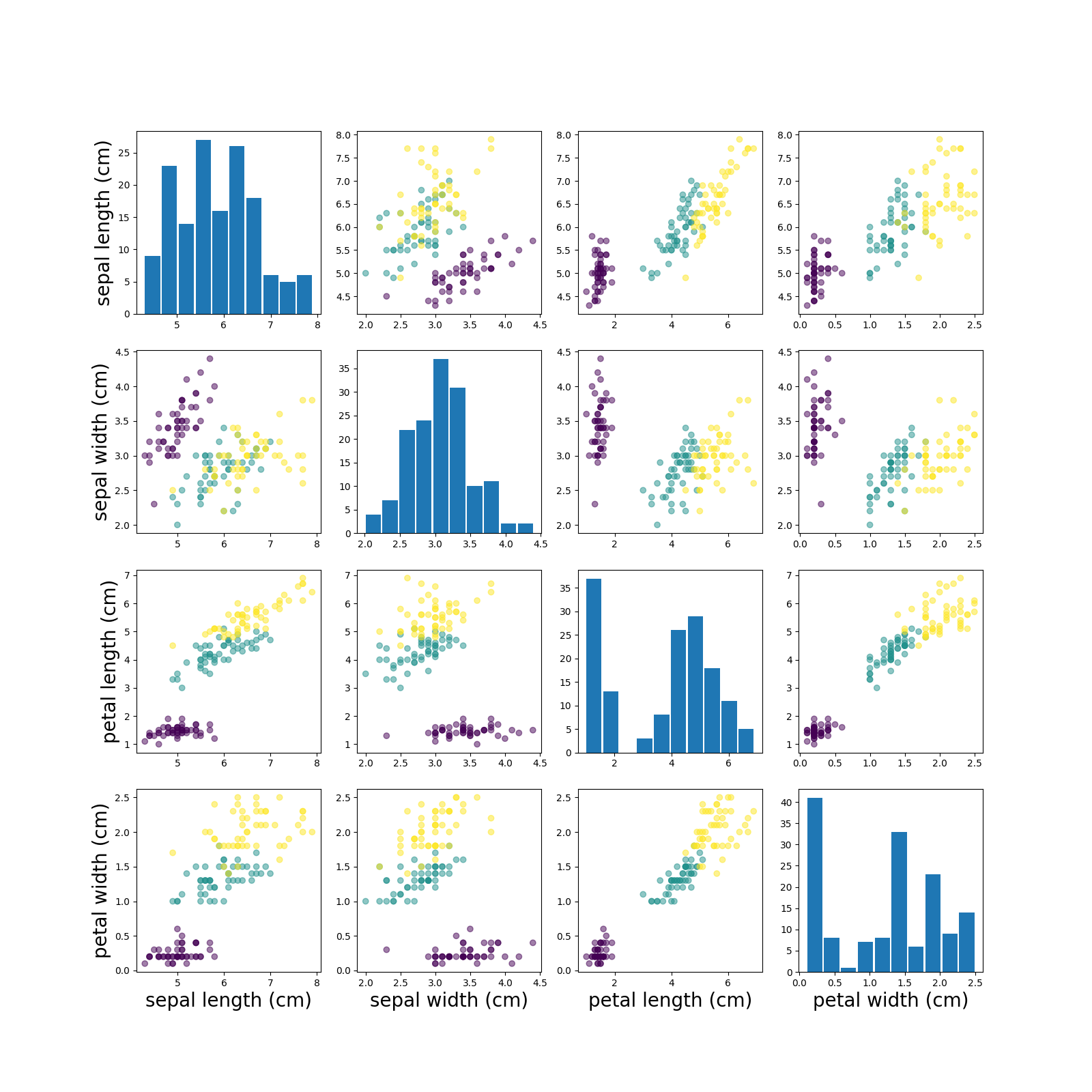
feature간 pairplot
def single_pair(axes, row, col, X, y, cls_dict, features):
color_list = ['purple', 'green', 'orange']
# histogram
if row == col:
data = X[:, row]
axes[row, col].hist(data, rwidth=0.9)
# scatter plot
else:
for key, val in cls_dict.items():
axes[row, col].scatter(val[:, col], val[:, row],
edgecolor=f'tab:{color_list[key]}',
color=color_list[key], alpha=0.5)
# labels
if col == 0:
axes[row, col].set(ylabel=features[row])
axes[row, col].set_ylabel(features[row], fontsize=20)
if row == len(features)-1:
axes[row, col].set(xlabel=features[col])
axes[row, col].set_xlabel(features[col], fontsize=20)
def iris_pairplot():
iris_X, iris_y, feature_names, species, n_feature, n_species = get_iris()
fig, axes = plt.subplots(nrows=4, ncols=4, figsize=(16, 16))
cls_dict = dict()
for cls in np.unique(iris_y):
cls_dict[cls] = iris_X[iris_y == cls]
for i in range(n_feature):
for j in range(n_feature):
single_pair(axes, i, j, iris_X, iris_y, cls_dict, feature_names)
Pairplot Refactoring (Full Code)
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
import numpy as np
def get_iris():
iris = load_iris()
for attr in dir(iris):
print(attr)
# DESCR
# data # data_module # feature_names # filename # frame # target # target_names
# 대문자는 행렬, 소문자는 벡터
iris_X = iris.data
iris_y = iris.target
feature_names = iris.feature_names
species = iris.target_names
n_feature = len(feature_names)
n_species = len(species)
return iris_X, iris_y, feature_names, species, n_feature, n_species
def single_pair2(axes, row, col, X, y, features):
# histogram
if row == col:
data = X[:, row]
axes[row, col].hist(data, rwidth=0.9)
# scatter plot
else:
axes[row, col].scatter(X[:, col], X[:, row], c=y, alpha=0.5)
# labels
if col == 0:
axes[row, col].set_ylabel(features[row], fontsize=20)
if row == len(features)-1:
axes[row, col].set_xlabel(features[col], fontsize=20)
def iris_pairplot_clean():
# code refactoring
iris_X, iris_y, feature_names, species, n_feature, n_species = get_iris()
fig, axes = plt.subplots(nrows=n_feature, ncols=n_feature, figsize=(16, 16))
for i in range(n_feature):
for j in range(n_feature):
single_pair2(axes, i, j, iris_X, iris_y, feature_names)
if __name__ == '__main__':
iris_pairplot_clean()
plt.show()코드 기전
- get_iris(): data 처리 코드
- single_pair2(): nxn 페어플랏의 싱글 플랏 차트 1개를 그리는 코드
1) 대각선(row가 col과 같은 경우)은 histogram
2) 그 외에는 scatter plot으로 2개의 feature간 교차 산점도 차트 그리기
3) 라벨링은 좌측 및 하단만 표기 - iris_pairplot_clean(): 메인 루틴 코드
1) 데이터 할당
2) nxn matplotlib 차트 설정 (n: feature 개수)
3) for loop으로 차트 번호 인덱싱하여 [a, b] 해당하는 인덱스의 개별 차트 그리기
리팩토링 시 고려한 점
1) Code Split
for 문 안에 돌아가는 반복 코드는 별도의 method로 split하고,
method 안에 있는 코드들이 의미적으로 일치하는 위치에 있는지 확인하여 재조정
2) Scatter plot c paremeter로 변경
기존에 scatter plot에서 c라는 parameter가 class 구분을 해주는지 모르고 데이터셋을 분리하여
3개의 scatter plot을 중첩했는데
분리해야할 이유가 없다면
-> target을 c에 설정하면 1개의 scatter plot만 그려도 class 별로 색이 구분되기 때문에 통합 데이터로 plotting 할 수 있음
3) Label 중복 코드 제거
subplot의 라벨 설정시 set_ylabel 함수 1개만으로 설정 가능
4) 하드코딩 제거
nrows=4, ncols=4 같이 숫자를 하드코딩하면 값이 틀어질 때 수정이 안되기때문에
기존의 get_iris 에서 받는 n_feature(피처 개수)를 row,col의 인자로 설정하여 동적으로 변경되도록 수정
fig, axes = plt.subplots(nrows=n_feature, ncols=n_feature, figsize=(16, 16))
💛 배운점/느낀점
- pandas 대신 numpy만 사용하여 구현해보았음. ndarray도 pandas의 iloc 처럼 인덱싱, 슬라이싱이 가능함
- pytorch의 tensor가 numpy와 유사하기 때문에, torch를 잘 사용하기 위해서 numpy를 더 잘 컨트롤할 수 있게 연습 필요
- 알고리즘을 작성할 때 먼저 머리속으로 설계하고 구현해보니까 어느정도 작성 후 테스트용으로 라인디버깅을 하게 되고 생산성이 올랐다는 느낌이 들었음
'Education > 새싹 TIL' 카테고리의 다른 글
| 새싹 AI데이터엔지니어 핀테커스 6주차 (화) - KNN (1) | 2023.10.10 |
|---|---|
| 새싹 AI데이터엔지니어 핀테커스 5주차 (금) - Boxplot, Numpy (1) | 2023.10.06 |
| 새싹 AI데이터엔지니어 핀테커스 5주차 (수) - matplotlib (2) (1) | 2023.10.04 |
| 새싹 AI데이터엔지니어 핀테커스 4주차 (금) - ML 관련 수학 (4) (0) | 2023.09.22 |
| 새싹 AI데이터엔지니어 핀테커스 4주차 (목) - ML 관련 수학 (3) (0) | 2023.09.21 |