728x90
LSTM
기존의 RNN에서 출력과 멀리 있는 정보를 기억할 수 없다는 단점을 보완하여 장/단기 기억을 가능하게 설계한 신경망의 구조
RNN의 기울기 소실, 폭발 문제를 보완할 수 있는 모델
0과 1 사이의 출력 값을 가지는 ht-1과 xt를 입력 값으로 받음
xt는 새로운 입력 값이고 ht-1은 이전 은닉층에서 입력되는 값
게이트를 통해서 정보가 추가되거나 삭제됨
망각 게이트(forget gate) :
이전 시간 스텝의 은닉 상태와 현재 입력을 기반으로 현재 시간 스텝의 셀 상태(cell state)에서 어떤 정보를 유지하고 어떤 정보를 삭제할지를 결정
입력 게이트(input gate) :
현재 시간 스텝의 입력 데이터를 어떤 양만큼 현재 시간 스텝의 셀 상태(cell state)에 추가할지를 결정하는 역할
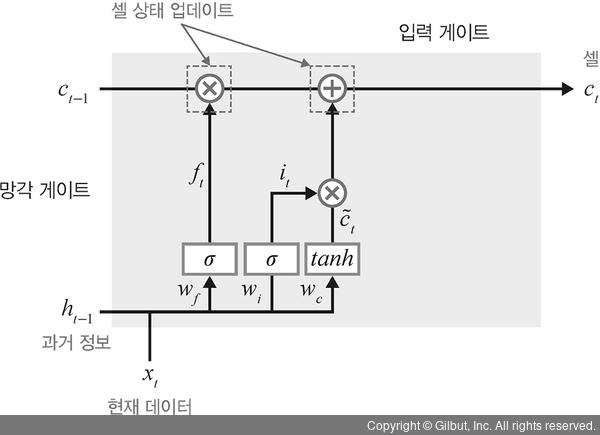
- 셀 상태가 업데이트 됨
- 0-1 출력값인 ht-1과 xt 를 입력값으로 받음
- 이때 xt는 새로운 입력값이고 ht-1는 이전 은닉층에서 입력되는 값
- 계산 값이 1이면 직전 정보를 메모리에 유지
- 계산 값이 0이면 초기화
- 계산한 값이 1이면 입력 xt가 들어올 수 있도록 허용(open)
LSTM 구조
- ct-1은 직전 상태이고, ft의 비율만큼 반영
- 새로운 상태값인 c~t를 it의 비율만큼 반영하여 결정
- 시그모이드 함수는 0, 1으로만 나옴
- 역전파는 ct-1 ct 셀라인을 기준으로 진행됨
망각게이트를 제외한 과정에는 시그모이드를 통과한 값과 tanh 를 곱한다
class LSTMCell(nn.Module):
def __init__(self, input_size, hidden_size, bias=True):
super(LSTMCell, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.bias = bias
self.x2h = nn.Linear(input_size, 4 * hidden_size, bias=bias)
self.h2h = nn.Linear(hidden_size, 4 * hidden_size, bias=bias)
self.reset_parameters()
def reset_parameters(self):
std = 1.0 / math.sqrt(self.hidden_size)
for w in self.parameters():
w.data.uniform_(-std, std)
def forward(self, x, hidden):
hx, cx = hidden
x = x.view(-1, x.size(1))
gates = self.x2h(x) + self.h2h(hx)
gates = gates.squeeze()
ingate, forgetgate, cellgate, outgate = gates.chunk(4, 1)
ingate = F.sigmoid(ingate)
forgetgate = F.sigmoid(forgetgate)
cellgate = F.tanh(cellgate)
outgate = F.sigmoid(outgate)
cy = torch.mul(cx, forgetgate) + torch.mul(ingate, cellgate)
hy = torch.mul(outgate, F.tanh(cy))
return (hy, cy)
LSTM 논문
http://www.bioinf.jku.at/publications/older/2604.pdf
-
망각, 입력,셀, 출력 게이트 (총 4개) 전부 다 입력과 은닉값이 입력됨
-
입력상태일 때 가중치와 은닉상태일 때 가중치가 다름 (가중치는 2개)
-
(wih, whh) x 4
-
input_size, 4 * hidden_size
-
squeeze() 차원을 1차원으로 줄이기
class LSTMModel(nn.Module):
def __init__(self, input_dim, hidden_dim, layer_dim, output_dim, bias=True):
super(LSTMModel, self).__init__()
self.hidden_dim = hidden_dim
self.layer_dim = layer_dim
self.lstm = LSTMCell(input_dim, hidden_dim, layer_dim)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
if torch.cuda.is_available():
h0 = Variable(torch.zeros(self.layer_dim, x.size(0), self.hidden_dim).cuda())
else:
h0 = Variable(torch.zeros(self.layer_dim, x.size(0), self.hidden_dim))
if torch.cuda.is_available():
c0 = Variable(torch.zeros(self.layer_dim, x.size(0), self.hidden_dim).cuda())
else:
c0 = Variable(torch.zeros(self.layer_dim, x.size(0), hidden_dim))
outs = []
cn = c0[0,:,:]
hn = h0[0,:,:]
for seq in range(x.size(1)):
hn, cn = self.lstm(x[:,seq,:], (hn,cn))
outs.append(hn)
out = outs[-1].squeeze()
out = self.fc(out)
return out
학습
seq_dim = 28
loss_list = []
iter = 0
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
if torch.cuda.is_available():
images = Variable(images.view(-1, seq_dim, input_dim).cuda())
labels = Variable(labels.cuda())
else:
images = Variable(images.view(-1, seq_dim, input_dim))
labels = Variable(labels)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
if torch.cuda.is_available():
loss.cuda()
loss.backward()
optimizer.step()
loss_list.append(loss.item())
iter += 1
if iter % 500 == 0:
correct = 0
total = 0
for images, labels in valid_loader:
if torch.cuda.is_available():
images = Variable(images.view(-1, seq_dim, input_dim).cuda())
else:
images = Variable(images.view(-1 , seq_dim, input_dim))
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
if torch.cuda.is_available():
correct += (predicted.cpu() == labels.cpu()).sum()
else:
correct += (predicted == labels).sum()
accuracy = 100 * correct / total
print('Iteration: {}. Loss: {}. Accuracy: {}'.format(iter, loss.item(), accuracy))
- correct 값: 맞춘 개수
Test
def evaluate(model, val_iter):
corrects, total, total_loss = 0, 0, 0
model.eval()
for images, labels in val_iter:
if torch.cuda.is_available():
images = Variable(images.view(-1, seq_dim, input_dim).cuda())
else:
images = Variable(images.view(-1 , seq_dim, input_dim)).to(device)
labels = labels.cuda()
logit = model(images).cuda()
loss = F.cross_entropy(logit, labels, reduction = "sum")
_, predicted = torch.max(logit.data, 1)
total += labels.size(0)
total_loss += loss.item()
corrects += (predicted == labels).sum()
avg_loss = total_loss / len(val_iter.dataset)
avg_accuracy = corrects / total
return avg_loss, avg_accuracy
스타벅스 주가 예측
train test set 분리
ms = MinMaxScaler()
ss = StandardScaler()
X_ss = ss.fit_transform(X)
y_ms = ms.fit_transform(y)
X_train = X_ss[:200, :]
X_test = X_ss[200:, :]
y_train = y_ms[:200, :]
y_test = y_ms[200:, :]
print("Training Shape", X_train.shape, y_train.shape)
print("Testing Shape", X_test.shape, y_test.shape)
- MinMaxScaler() : 데이터의 모든 값이 0~1 사이에 존재하도록 분산 조정
- StandardScaler(): 데이터가 평균 0, 분산 1이되도록 분산 조정
X_train_tensors = Variable(torch.Tensor(X_train))
X_test_tensors = Variable(torch.Tensor(X_test))
y_train_tensors = Variable(torch.Tensor(y_train))
y_test_tensors = Variable(torch.Tensor(y_test))
X_train_tensors_f = torch.reshape(X_train_tensors, (X_train_tensors.shape[0], 1, X_train_tensors.shape[1]))
X_test_tensors_f = torch.reshape(X_test_tensors, (X_test_tensors.shape[0], 1, X_test_tensors.shape[1]))
print("Training Shape", X_train_tensors_f.shape, y_train_tensors.shape)
print("Testing Shape", X_test_tensors_f.shape, y_test_tensors.shape)
모델
class LSTM(nn.Module):
def __init__(self, num_classes, input_size, hidden_size, num_layers, seq_length):
super(LSTM, self).__init__()
self.num_classes = num_classes
self.num_layers = num_layers
self.input_size = input_size
self.hidden_size = hidden_size
self.seq_length = seq_length
self.lstm = nn.LSTM(input_size=input_size, hidden_size=hidden_size,
num_layers=num_layers, batch_first=True)
self.fc_1 = nn.Linear(hidden_size, 128)
self.fc = nn.Linear(128, num_classes)
self.relu = nn.ReLU()
def forward(self,x):
h_0 = Variable(torch.zeros(self.num_layers, x.size(0), self.hidden_size))
c_0 = Variable(torch.zeros(self.num_layers, x.size(0), self.hidden_size))
output, (hn, cn) = self.lstm(x, (h_0, c_0))
hn = hn.view(-1, self.hidden_size)
out = self.relu(hn)
out = self.fc_1(out)
out = self.relu(out)
out = self.fc(out)
return out
- x.size(0) 에는 데이터 개수 200개
- hn.view(-1, self.hidden_size) : 1차원으로 변경
epoch 등 설정
num_epochs = 1000
learning_rate = 0.0001
input_size = 5
hidden_size = 2
num_layers = 1
num_classes = 1
# self, num_classes, input_size, hidden_size, num_layers, seq_length
model = LSTM(num_classes, input_size, hidden_size, num_layers, X_train_tensors_f.shape[1])
criterion = torch.nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
- input_size = 5 입력 데이터 셋의 컬럼 개수
- hidden_size =2 은닉층의 뉴런/유닛 개숴
- num_layers = 1 LSTM 계층의 개수
- X_train_tensors_f.shape[1] = time step (1단위 묶음 time step 개수)
- = torch.Size([200, 1, 5])
- 200: 데이터 샘플의 개수 (배치 크기)
- 1: 시퀀스 길이 (
seq_length가 10이라면 각 샘플이 10개의 시간 단계로 구성됨을 나타냄) - 5: 각 시간 단계에서의 특성(feature)의 개수 (또는 출력 차원 수)
학습
for epoch in range(num_epochs):
outputs = model.forward(X_train_tensors_f)
optimizer.zero_grad()
loss = criterion(outputs, y_train_tensors)
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print("Epoch: %d, loss: %1.5f" % (epoch, loss.item()))
예측 결과
train_predict = model(df_x_ss)
predicted = train_predict.data.numpy()
label_y = df_y_ms.data.numpy()
predicted= ms.inverse_transform(predicted)
label_y = ms.inverse_transform(label_y)
plt.figure(figsize=(10,6))
plt.axvline(x=200, c='r', linestyle='--')
plt.plot(label_y, label='Actual Data')
plt.plot(predicted, label='Predicted Data')
plt.title('Time-Series Prediction')
plt.legend()
plt.show()

Bigger Epochs
import os
import time
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torch.utils.data import TensorDataset, DataLoader
from torch.autograd import Variable
from tqdm import tqdm_notebook
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.model_selection import train_test_split
# Check if CUDA is available and set the device accordingly
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
data = pd.read_csv('SBUX_max.csv')
print(data.dtypes)
data['Date'] = pd.to_datetime(data['Date'])
data.set_index('Date', inplace=True)
data['Volume'] = data['Volume'].astype(float)
x = data.iloc[:, :-1]
y = data.iloc[:, 5:6]
print(x)
print(y)
ms = MinMaxScaler()
ss = StandardScaler()
x_ss = ss.fit_transform(x)
y_ms = ms.fit_transform(y)
x_train = x_ss[:200, :]
x_test = x_ss[200:, :]
y_train = y_ms[:200, :]
y_test = y_ms[200:, :]
print("Training Shape", x_train.shape, y_train.shape)
print("Testing Shape", x_test.shape, y_test.shape)
# Convert data to tensors and move to the appropriate device
x_train_tensors = Variable(torch.Tensor(x_train)).to(device)
x_test_tensors = Variable(torch.Tensor(x_test)).to(device)
y_train_tensors = Variable(torch.Tensor(y_train)).to(device)
y_test_tensors = Variable(torch.Tensor(y_test)).to(device)
x_train_tensors_f = torch.reshape(x_train_tensors, (x_train_tensors.shape[0], 1, x_train_tensors.shape[1]))
x_test_tensors_f = torch.reshape(x_test_tensors, (x_test_tensors.shape[0], 1, x_test_tensors.shape[1]))
print("Training Shape", x_train_tensors_f.shape, y_train_tensors.shape)
print("Testing Shape", x_test_tensors_f.shape, y_test_tensors.shape)
class LSTM(nn.Module):
def __init__(self, num_classes, input_size, hidden_size, num_layers, seq_length):
super(LSTM, self).__init__()
self.num_classes = num_classes
self.num_layers = num_layers
self.input_size = input_size
self.hidden_size = hidden_size
self.seq_length = seq_length
self.lstm = nn.LSTM(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers, batch_first=True)
self.fc_1 = nn.Linear(hidden_size, 128)
self.fc = nn.Linear(128, num_classes)
self.relu = nn.ReLU()
def forward(self, x):
h_0 = Variable(torch.zeros(self.num_layers, x.size(0), self.hidden_size)).to(device)
c_0 = Variable(torch.zeros(self.num_layers, x.size(0), self.hidden_size)).to(device)
output, (hn, cn) = self.lstm(x, (h_0, c_0))
hn = hn.view(-1, self.hidden_size)
out = self.relu(hn)
out = self.fc_1(out)
out = self.relu(out)
out = self.fc(out)
return out
# Variable values
num_epochs = 20000
learning_rate = 0.0001
input_size = 5
hidden_size = 2
num_layers = 1
num_classes = 1
model = LSTM(num_classes, input_size, hidden_size, num_layers, x_train_tensors_f.shape[1])
criterion = torch.nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
model = model.to(device)
criterion = criterion.to(device)
# Model training
for epoch in range(num_epochs):
outputs = model.forward(x_train_tensors_f)
optimizer.zero_grad()
loss = criterion(outputs, y_train_tensors)
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print("Epoch: %d, loss: %1.5f" % (epoch, loss.item()))
df_x_ss = ss.transform(data.iloc[:, :-1])
df_y_ms = ms.transform(data.iloc[:, -1:])
df_x_ss = Variable(torch.Tensor(df_x_ss)).to(device)
df_y_ms = Variable(torch.Tensor(df_y_ms)).to(device)
df_x_ss = torch.reshape(df_x_ss, (df_x_ss.shape[0], 1, df_x_ss.shape[1]))
# Model prediction and visualization
train_predict = model(df_x_ss)
predicted = train_predict.data.cpu().numpy()
label_y = df_y_ms.data.cpu().numpy()
predicted = ms.inverse_transform(predicted)
label_y = ms.inverse_transform(label_y)
plt.figure(figsize=(10, 6))
plt.axvline(x=200, c='r', linestyle='--')
plt.plot(label_y, label='Actual Data')
plt.plot(predicted, label='Predicted Data')
plt.title('Time-Series Prediction')
plt.legend()
plt.show()

예측을 거의 못한다고할 수 있겠다… 😱
반응형
'Education > ICT AI 중급' 카테고리의 다른 글
| 4주차_16 필기 (RNN) (0) | 2023.10.15 |
|---|---|
| 4주차_15 필기 (ResNet) (1) | 2023.10.15 |
| 4주차_14 필기 (VGGNet) (0) | 2023.10.15 |
| 3주차_13 필기 (LeNet, Alexnet) (2) | 2023.10.15 |
| 3주차_12 필기 (전이학습) (1) | 2023.10.15 |