ResNet
마이크로소프트에서 개발한 알고리즘으로 “Deep Residual Learning for Image
Recognition”이라는 논문에서 발표
깊어진 신경망을 효과적으로 학습하기 위한 방법으로 레지듀얼(residual) 개
념을 고안한 것
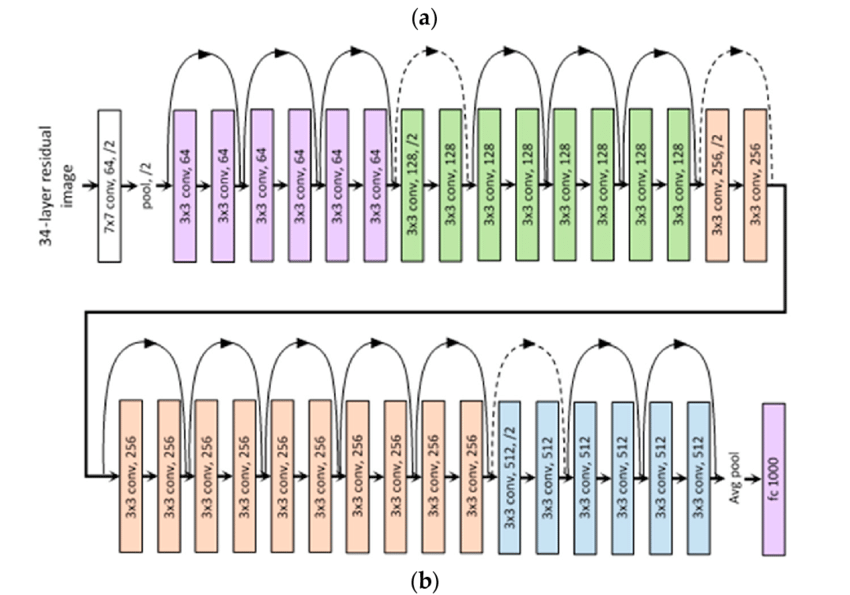
- 색깔 단위로 블록(합성곱층 묶음)
- 계층을 계속 쌓다보면 병목 블록 발생
- ResNet34 = 기본 블록 ResNet60 = 병목 블록
- 병목 블록은 파라미터가 깊어졌음에도 감소
- 3×3 합성곱층 앞뒤로 1×1 합성곱층이 붙어 있음
- 아이덴티티 매핑(숏컷)
- 아이덴티티 매핑이란 입력 x가 어떤 함수를 통과하더라도 다시 x라는 형태로 출력되도록 함
def forward(self, x):
i = x #(28, 28, 64)
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
if self.downsample is not None:
i = self.downsample(i) # (28, 28, 64)
x += I # identity mapping
x = self.relu(x)
return x
- downsample: 특성맵(feature map) 크기를 줄이기 위한 것으로 풀링과 같은 역할을 함
- 채널 수가 64 -> 128이 되었는데, 합성곱층의 stride가 2로 늘어나 (14, 14, 128)로 바뀜
- 프로젝션 숏컷(projection-shortcut) : 입력 및 출력 차원이 동일하지 않고 입력의 차원을 출력에 맞추어 변경해야 하는 것
Student = namedtuple('Student', ['name', 'age', 'DOB'])
- namedtuple 인덱스 뿐만 아니라 키 값으로 데이터에 접근 가능할 수 있음
class ImageTransform():
def __init__(self, resize, mean, std):
self.data_transform = {
'train': transforms.Compose([
transforms.RandomResizedCrop(resize, scale=(0.5, 1.0)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean, std)
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(resize),
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
}
def __call__(self, img, phase):
return self.data_transform[phase](img)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channels, out_channels, stride = 1, downsample = False):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size = 3,
stride = stride, padding = 1, bias = False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size = 3,
stride = 1, padding = 1, bias = False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace = True)
if downsample:
conv = nn.Conv2d(in_channels, out_channels, kernel_size = 1,
stride = stride, bias = False)
bn = nn.BatchNorm2d(out_channels)
downsample = nn.Sequential(conv, bn)
else:
downsample = None
self.downsample = downsample
def forward(self, x):
i = x
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
if self.downsample is not None:
i = self.downsample(i)
x += i
x = self.relu(x)
return x
- downsample : pooling할지 여부
- downsample이 True일 경우 1x1 합성곱층이 다운샘플링함
- 블록 내에 다운 샘플링을 해서 입력과 출력의 차원을 매칭시키는것
- 더 깊은 네트워크에 사용, gradient 소실 문제 완화
bottleneck
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_channels, out_channels, stride = 1, downsample = False):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size = 1, stride = 1, bias = False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size = 3, stride = stride, padding = 1, bias = False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.conv3 = nn.Conv2d(out_channels, self.expansion * out_channels, kernel_size = 1, stride = 1, bias = False)
self.bn3 = nn.BatchNorm2d(self.expansion * out_channels)
self.relu = nn.ReLU(inplace = True)
if downsample:
conv = nn.Conv2d(in_channels, self.expansion * out_channels, kernel_size = 1, stride = stride, bias = False)
bn = nn.BatchNorm2d(self.expansion * out_channels)
downsample = nn.Sequential(conv, bn)
else:
downsample = None
self.downsample = downsample
def forward(self, x):
i = x
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.conv3(x)
x = self.bn3(x)
if self.downsample is not None:
i = self.downsample(i)
x += i
x = self.relu(x)
return x
- expansion = 4 -> Resnet에서 병목 블럭을 정의하기 위한 하이퍼 파라미터 - 숫자 변경해도됨
- self.conv3 = nn.Conv2d(out_channels, self.expansion * out_channels, kernel_size = 1, stride = 1, bias = False)
- 1x1 합성곱층, 또한 다음 계층의 입력 채널 수와 일치하도록 self.expansion(4) x out_channels 함
- 1x1로 줄여서 특징 추출 후 확장
- bn = nn.BatchNorm2d(self.expansion * out_channels) 여기서 4배 확장됨
summary
기본 블록은 3x3 합성곱층 두 개를 갖는 반면, 병목 블록은 1x1 합성곱층, 3x3 합성곱층, 1x1 합성곱층 구조를 가짐
1x1에서 파라미터 감소 효과
아이덴티티 매핑과 병목 블록으로 ResNet 네트워크에 더욱 깊은 계층을 쌓을 수 있게 됨
ResNet 모델 네트워크
class ResNet(nn.Module):
def __init__(self, config, output_dim, zero_init_residual=False):
super().__init__()
block, n_blocks, channels = config
self.in_channels = channels[0]
assert len(n_blocks) == len(channels) == 4
self.conv1 = nn.Conv2d(3, self.in_channels, kernel_size = 7, stride = 2, padding = 3, bias = False)
self.bn1 = nn.BatchNorm2d(self.in_channels)
self.relu = nn.ReLU(inplace = True)
self.maxpool = nn.MaxPool2d(kernel_size = 3, stride = 2, padding = 1)
self.layer1 = self.get_resnet_layer(block, n_blocks[0], channels[0])
self.layer2 = self.get_resnet_layer(block, n_blocks[1], channels[1], stride = 2)
self.layer3 = self.get_resnet_layer(block, n_blocks[2], channels[2], stride = 2)
self.layer4 = self.get_resnet_layer(block, n_blocks[3], channels[3], stride = 2)
self.avgpool = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(self.in_channels, output_dim)
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def get_resnet_layer(self, block, n_blocks, channels, stride = 1):
layers = []
if self.in_channels != block.expansion * channels:
downsample = True
else:
downsample = False
layers.append(block(self.in_channels, channels, stride, downsample))
for i in range(1, n_blocks):
layers.append(block(block.expansion * channels, channels))
self.in_channels = block.expansion * channels
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
h = x.view(x.shape[0], -1)
x = self.fc(h)
return x, h
- config : resnet 정보를 담은 tuple data (block, n_blocks, channels)
- zero_init_residual : 잔차 연결 가중치를 0으로 할지 여부 (True면 0 Fale면 유지)
- in_channels = 입력 이미지 채널 수의 0번째에 있는 값 [3,224,224] 에서 3
- assert 부분 줄에 False가 나오면 에러발생
- len(n_blocks) == len(channels) == 4 블록크기, 채널크기가 전부 4여야 다음 진행
- if zero_init_residual:
- nn.init.constant_ : 가중치(weight)나 편향(bias)과 같은 모델 파라미터들을 특정한 상수값으로 초기화
- bottleneck 인 경우 bn3의 가중치에서 모든 원소가 0.0으로 설정
- basicblock 인 경우 bn2의 가중치에서 모든 원소가 0.0으로 설정
참고 논문
https://arxiv.org/abs/1706.02677
config
ResNetConfig = namedtuple('ResNetConfig', ['block', 'n_blocks', 'channels'])
resnet18_config = ResNetConfig(block = BasicBlock,
n_blocks = [2,2,2,2],
channels = [64, 128, 256, 512])
resnet34_config = ResNetConfig(block = BasicBlock,
n_blocks = [3,4,6,3],
channels = [64, 128, 256, 512])
resnet50_config = ResNetConfig(block = Bottleneck,
n_blocks = [3, 4, 6, 3],
channels = [64, 128, 256, 512])
resnet101_config = ResNetConfig(block = Bottleneck,
n_blocks = [3, 4, 23, 3],
channels = [64, 128, 256, 512])
resnet152_config = ResNetConfig(block = Bottleneck,
n_blocks = [3, 8, 36, 3],
channels = [64, 128, 256, 512])
pretrained_model = models.resnet50(pretrained=True)
print(pretrained_model)
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=2048, out_features=2, bias=True)
)
모델 학습 정확도 측정 함수 정의
def calculate_topk_accuracy(y_pred, y, k = 2):
with torch.no_grad():
batch_size = y.shape[0]
_, top_pred = y_pred.topk(k, 1)
top_pred = top_pred.t()
correct = top_pred.eq(y.view(1, -1).expand_as(top_pred))
correct_1 = correct[:1].reshape(-1).float().sum(0, keepdim = True)
correct_k = correct[:k].reshape(-1).float().sum(0, keepdim = True)
acc_1 = correct_1 / batch_size
acc_k = correct_k / batch_size
return acc_1, acc_k
모델 학습 함수 정의
def train(model, iterator, optimizer, criterion, device):
epoch_loss = 0
epoch_acc_1 = 0
epoch_acc_5 = 0
model.train()
for (x, y) in iterator:
x = x.to(device)
y = y.to(device)
optimizer.zero_grad()
y_pred = model(x)
loss = criterion(y_pred[0], y)
acc_1, acc_5 = calculate_topk_accuracy(y_pred[0], y)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc_1 += acc_1.item()
epoch_acc_5 += acc_5.item()
epoch_loss /= len(iterator)
epoch_acc_1 /= len(iterator)
epoch_acc_5 /= len(iterator)
return epoch_loss, epoch_acc_1, epoch_acc_5
def evaluate(model, iterator, criterion, device):
epoch_loss = 0
epoch_acc_1 = 0
epoch_acc_5 = 0
model.eval()
with torch.no_grad():
for (x, y) in iterator:
x = x.to(device)
y = y.to(device)
y_pred = model(x)
loss = criterion(y_pred[0], y)
acc_1, acc_5 = calculate_topk_accuracy(y_pred[0], y)
epoch_loss += loss.item()
epoch_acc_1 += acc_1.item()
epoch_acc_5 += acc_5.item()
epoch_loss /= len(iterator)
epoch_acc_1 /= len(iterator)
epoch_acc_5 /= len(iterator)
return epoch_loss, epoch_acc_1, epoch_acc_5
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
학습 시작
best_valid_loss = float('inf')
EPOCHS = 10
for epoch in range(EPOCHS):
start_time = time.monotonic()
train_loss, train_acc_1, train_acc_5 = train(model, train_iterator, optimizer, criterion, device)
valid_loss, valid_acc_1, valid_acc_5 = evaluate(model, valid_iterator, criterion, device)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'ResNet-model.pt')
end_time = time.monotonic()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
print(f'Epoch: {epoch+1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train Acc @1: {train_acc_1*100:6.2f}% | ' \
f'Train Acc @5: {train_acc_5*100:6.2f}%')
print(f'\tValid Loss: {valid_loss:.3f} | Valid Acc @1: {valid_acc_1*100:6.2f}% | ' \
f'Valid Acc @5: {valid_acc_5*100:6.2f}%')
객체 인식을 위한 신경망
이미지나 영상 내에 있는 객체를 식별하는 컴퓨터 비전 기술
1단계 객체 인식은 이 두 문제(분류와 위치 검출)를 동시에 행하는 방법: YOLO(You Only Look Once) 계열과 SSD 계열
2단계 객체 인식은 이 두 문제를 순차적으로 행하는 방법 : R-CNN
R-CNN
CNN과 이미지에서 객체가 있을 만한 영역을 제안해 주는 후보 영역 알고리즘을 결합한 알고리즘
공간 피라미드 풀링
입력 이미지의 크기에 관계없이 합성곱층을 통과시키고, 완전연결층에 전달되기 전에 특성 맵들을 동일한 크기로 조절해 주는 풀링층을 적용하는 기법
FastR-CNN(Fast Region-based CNN)
R-CNN의 속도 문제를 개선하려고 RoI 풀링을 도입
선택적 탐색에서 찾은 바운딩 박스 정보가 CNN을 통과하면서 유지
최종 CNN 특성 맵은 풀링을 적용하여 완전연결층을 통과하도록 크기를 조정
RoI 풀링
크기가 다른 특성 맵의 영역마다 스트라이드를 다르게 최대 풀링을 적용하여 결괏값 크기를 동일하게 맞추는 방법
이미지 분할을 위한 신경망
이미지 분할(image segmentation)은 신경망을 훈련시켜 이미지를 픽셀 단위로 분할하는 것
역합성곱은 이와 반대로 특성 맵 크기를 증가시키는 방식으로 동작
- 각각의 픽셀 주위에 제로 패딩(zero-padding)을 추가
- 이렇게 패딩된 것에 합성곱 연산을 수행
https://arxiv.org/abs/1505.04597
https://github.com/milesial/Pytorch-UNet
'Education > ICT AI 중급' 카테고리의 다른 글
| 4주차_17 필기 (LSTM) (0) | 2023.10.15 |
|---|---|
| 4주차_16 필기 (RNN) (0) | 2023.10.15 |
| 4주차_14 필기 (VGGNet) (0) | 2023.10.15 |
| 3주차_13 필기 (LeNet, Alexnet) (2) | 2023.10.15 |
| 3주차_12 필기 (전이학습) (1) | 2023.10.15 |