validation set을 만드는 이유:
트레이닝과 테스트 데이터만 있으면 테스트 데이터에 의해 최종 모형의 hyper parameter가 결정된다
-> 모형이 테스트 데이터에 의존하는 문제가 생김
validataion data는 hyper parameter 설정을 위해 사용
training data is for parameter
그리드 서치는 머신러닝 과정에서 관심있는 매개변수들을 대상으로 학습 가능하도록 만드는 방식
엔트로피
entropy: 확률변수의 불확실성 정도를 측정하기 위해 사용
cross entropy:
P(x) = 실제 모형의 분포
Q(x) = 추정 모형의 분포
KLD(Kullback-Leibler-Divergence) : 상대적 엔트로피
DKL…
NLL…
로그 가능도 함수를 최대화 하는 것은 크로스 엔트로피를 최소화 하는 것
손실함수
L1 loss
MAE
L2 loss
MSE
RMSE
R = root, RMSE는 이상치와 상관 없이 안정된 값
-> 이상치에 중점을 두고 싶다면 MSE도 사용
manhattan distance
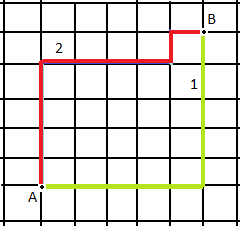
빨간 줄을 x축, y축으로 밀면 연두색 줄이 됨
B의 좌표가 (u, v) 라고 하면
모형 성능평가
confusion matrix: 혼동행렬
2차원
| 실제/예측 | 양성 | 음성 |
|---|---|---|
| 양성 | TP | FN |
| 음성 | FP | TN |
3차원 (3 classes)
| 실제/예측 | 클래스1 | 클래스2 | 클래스3 |
|---|---|---|---|
| 클래스1 | TP | FN | FN |
| 클래스2 | FP | TN | TN |
| 클래스3 | FP | TN | TN |
FP 자리 보는 방법: 첫 번째 자리는 실제, 두 번째 자리는 예측
정밀도 (precision): 양성으로 예측한 것 중 실제로 양성인 경우
리콜, 민감도 (recall, sensitivity): 실제로 양성인 사람이 양성으로 예측되는 경우
분모는 양성 케이스 전부
FN: N 음성으로 예측했는데 F 틀리고 사실 양성인 경우
특이도 (specificity): 실제로 음성인 사람이 음성으로 예측되는 경우
False Positive Rate: 실제로 음성인 사람이 양성으로 예측되는 경우
정확도 (accuracy): 전체 데이터 중 정답으로 분류되는 비율
ROC 커브: x 축에 FPR을 놓고 y축에는 민감도의 값을 비교
receiver operating characteristic
분류문제에서의 성능평가
- 정확도
I 는 지시함수(indicator function)라서 괄호안이 True면 1 False면 0
- F1 Score
F1 score는 0~1의 값 & 1에 가까울 수록 높은 성능
precision과 recall의 조화 평균 값
- confusion matrix: 예측값과 실제값의 빈도를 행렬로 확인
- classification report
회귀 문제에서의 성능 평가
Mean Absolute Error = MSE
Means Squared Error = MSE
R2 Score (R 제곱값): 전체 모형에서 설명 가능한 분산의 비율
0~1 사잇값, 1에 가까울 수록 높은 성능
군집 문제에서의 성능 평가
실루엣 스코어 (silhouette score): -1~1 사잇값, 높을수록 좋은 성능
a= 같은 클래스 내에서 특정 데이터 포인트와 나머지 데이터 와의 평균 거리
b= 특정 데이터 포인트와 2번째로 가까운 집단 내 포인트간 평균거리
'AI > Books' 카테고리의 다른 글
| 선형대수와 통계학으로 배우는 머신러닝 - Chap9 앙상블 학습 (0) | 2023.12.25 |
|---|---|
| 선형대수와 통계학으로 배우는 머신러닝 - Chap8 지도 학습 (1) | 2023.12.25 |
| 선형대수와 통계학으로 배우는 머신러닝 - Chap6 머신러닝 데이터 라이브러리 (Scikit-Learn) (0) | 2023.12.25 |
| 선형대수와 통계학으로 배우는 머신러닝 - Chap4 머신러닝을 위한 통계학 및 파이토치 (1) | 2023.12.25 |
| 선형대수와 통계학으로 배우는 머신러닝 - Chap3 선형대수 (0) | 2023.12.25 |