728x90
2023-12-12 69th Class
트랜스포머 주가 예측모델 하이퍼파라미터 튜닝
config
class Config:
device = get_device()
# data
base_dir = './../../../../src/ch3_ta/final_entry/'
file_paths = get_all_csv_files(base_dir)[:30]
n_files = len(file_paths)
use_cols = ['High', 'Low', 'Close', 'Change', 'volume_obv',
'volatility_kchi', 'trend_ema_slow']
len_feature_columns = len(use_cols)
label_columns = [2]
n_labels = len(label_columns)
shuffle_train_data = False
test_size = 0.2
train_size = 0.8
# train
predict_day = 1
seq_len = 10
batch_size = 8
learning_rate = 0.0001
epochs = 300 # 300
random_seed = 42
# to save model
model_base_dir = '../../../model/'
save_every = 50 # 50
do_continue_train = False # 每次训练把上一次的final_state作为下一次的init_state,仅用于RNN类型模型,目前仅支持pytorch
# model_to_load = 'model_state_dict_epoch_3_20231210121644.pt' model_to_load = 'model_state_dict_epoch_301_2312122015.pt'
# to save visualization figures
vis_base_dir = './visual/'
model
class CrossAttentionTransformer(nn.Module):
def __init__(self, config):
super(CrossAttentionTransformer, self).__init__()
self.config = config
# 리니어 레이어를 담을 리스트
# self.linear_layers = nn.ModuleList([nn.Linear(4, 1) for _ in range(10)])
self.linear_layers = nn.ModuleList([nn.Linear(in_features=config.len_feature_columns, out_features=config.n_labels, dtype=torch.float32).to(config.device) for _ in range(config.n_files)])
self.pos_embedding_ticker = PositionalEmbedding(config.n_files, config.seq_len)
# https://github.com/lucidrains/performer-pytorch
self.performer_ticker = Performer(
dim=config.seq_len, # 트랜스포머의 입력 임베딩 및 출력 차원입니다. 이는 시퀀스의 길이 또는 특성의 차원을 나타냅니다.
depth=4, # 트랜스포머의 레이어 수입니다. 이는 트랜스포머가 몇 개의 층으로 구성되어 있는지를 나타냅니다.
heads=2, # 멀티 헤드 어텐션에서 사용되는 어텐션 헤드의 개수입니다. 멀티 헤드 어텐션은 모델이 여러 관점에서 정보를 취합할 수 있도록 합니다.
dim_head=config.seq_len // 2, # 각 어텐션 헤드의 차원입니다. 어텐션 헤드는 입력 특성을 서로 다른 부분 공간으로 매핑하여 모델이 다양한 특징을 학습할 수 있게 합니다.
causal=False # 캐주얼 어텐션 여부를 나타냅니다. 캐주얼 어텐션은 각 위치에서 이전 위치만 참조하도록 하는데, 이것은 주로 시퀀스 데이터에서 다음 값을 예측하는 데 사용됩니다.
).to(config.device)
self.pos_embedding_time = PositionalEmbedding(config.seq_len, config.n_files)
self.performer_time = Performer(
dim=config.n_files,
depth=4,
heads=2,
dim_head=config.n_files // 2,
causal=False
).to(config.device)
def forward(self, x):
# 리니어 레이어를 통과하여 결과를 리스트에 저장
# linear_outputs = [linear(x[:, i * 4:(i + 1) * 4]) for i, linear in enumerate(self.linear_layers)]
linear_outputs = None
for i, linear in enumerate(self.linear_layers):
# (Batch, seq_len, len_feature_columns)
y_start, y_end = 0, self.config.seq_len
x_start, x_end = i * self.config.len_feature_columns, (i + 1) * self.config.len_feature_columns
curr_seq_feats = x[:, y_start:y_end, x_start:x_end]
curr_output = linear(curr_seq_feats)
if linear_outputs is None:
linear_outputs = curr_output
continue
linear_outputs = torch.cat([linear_outputs, curr_output], dim=2)
outputs = linear_outputs.permute(0, 2, 1)
outputs = self.pos_embedding_ticker(outputs)
outputs = self.performer_ticker(outputs)
outputs = outputs.permute(0, 2, 1)
outputs = self.pos_embedding_time(outputs)
outputs = self.performer_time(outputs)
outputs = outputs.mean(dim=1)
return outputs
result

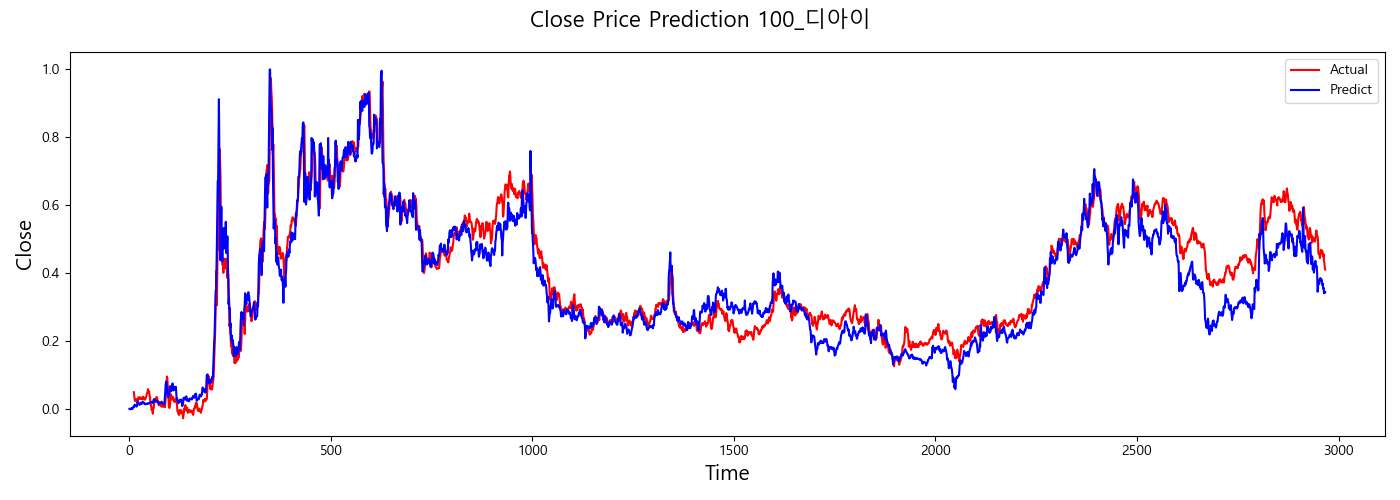
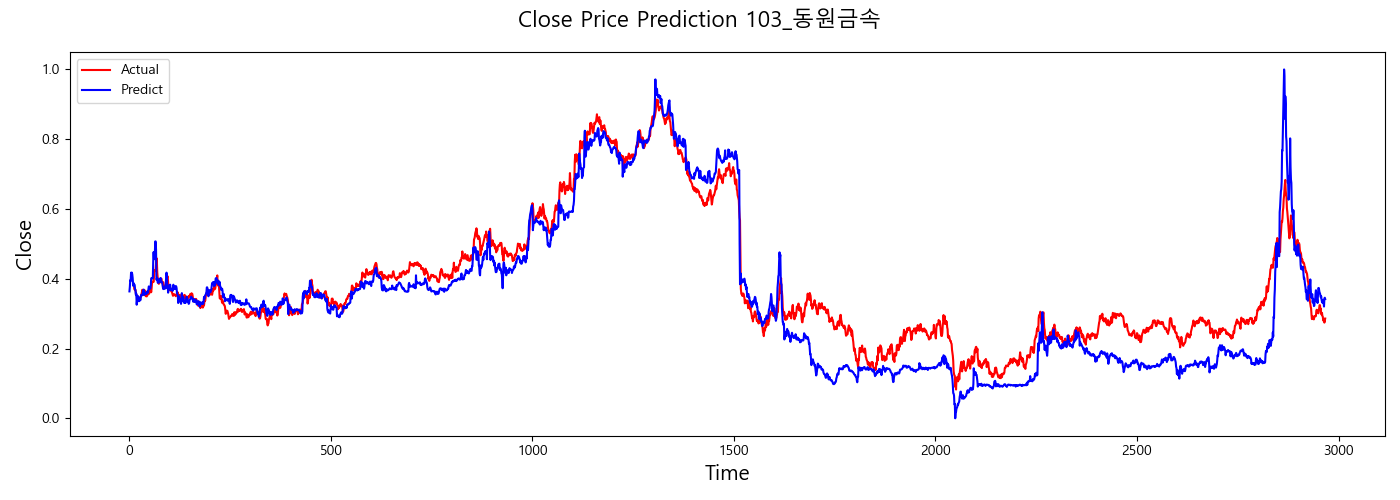
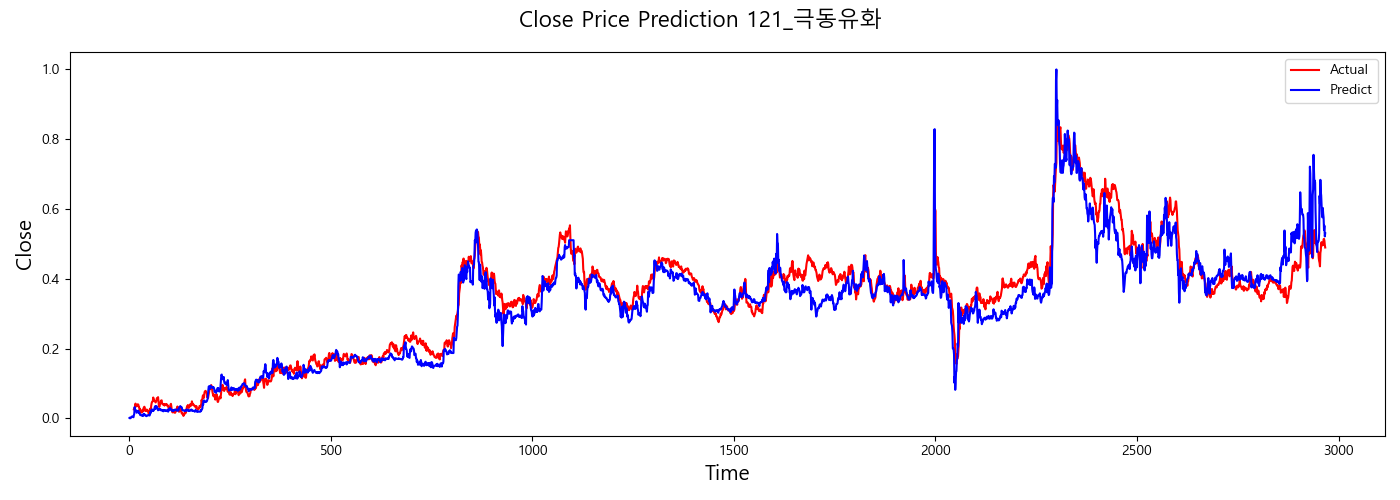
반응형
'Education > 새싹 TIL' 카테고리의 다른 글
| 새싹 AI데이터엔지니어 핀테커스 15주차 (목) - PJT 9 Presentation (0) | 2024.01.02 |
|---|---|
| 새싹 AI데이터엔지니어 핀테커스 15주차 (수) - PJT 8 Profit Rate Calculator (0) | 2023.12.17 |
| 새싹 AI데이터엔지니어 핀테커스 15주차 (월) - PJT 6 High Risk Stock Strategy (0) | 2023.12.12 |
| 새싹 AI데이터엔지니어 핀테커스 14주차 (금) - PJT 5 CrossAttn Transformer v1 & To do List (0) | 2023.12.09 |
| 새싹 AI데이터엔지니어 핀테커스 14주차 (목) - PJT 4 Transformer Study (0) | 2023.12.07 |