- 비볼록 함수
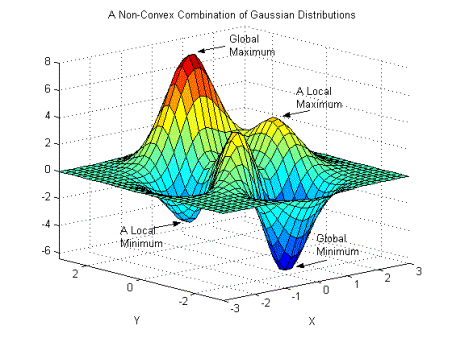
Global Minimum: 목표 함수 그래프 전체를 고려했을 때 최솟값
Local Minimum: 그래프 내 일부만 고려했을 때 최솟값
- Saddle point

기울기가 0이지만 극값이 아닌 지점
경사하강법은
- 최적인 줄 알았던 값인 global minimum이 사실은 local minimum인 문제가 발생할 수 있음
- Saddle Point에서 미분값이 0이지만 극값이 아닌데도 더이상 파라미터를 업데이트 하지 않아서 이 지점을 벗어날 수 없음
Momentum
AdaGrad: Feature별로 학습률(Learning rate)을 Adaptive하게, 즉 다르게 조절
Adagrad는 각각의 파라미터(가중치)를 업데이트할 때, 그 동안 사용된 모든 기울기의 제곱값을 더함
파라미터가 자주 변하는 기울기가 큰 경우에는 학습률을 작게 조절하고, 기울기가 적게 변하는 파라미터에는 더 큰 학습률을 적용
RMSProp
https://blog.naver.com/PostView.naver?blogId=geojerich&logNo=222160083790
활성화 함수
퍼셉트론(Perceptron)의 출력값을 결정하는 비선형함수
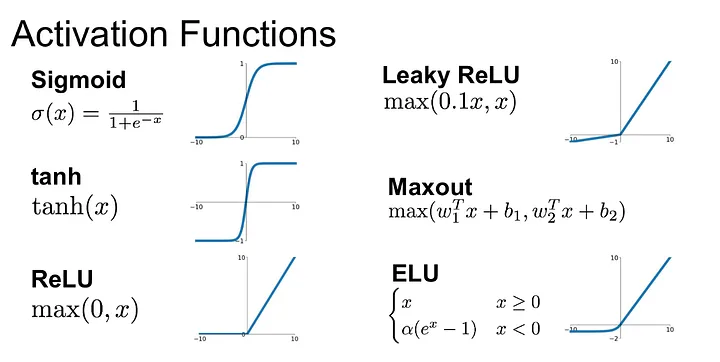
sigmoid 함수
로지스틱 회귀분석 또는 Neural Network의 Binary classification 마지막 레이어의 함수로 사용
로지스틱 회귀분석-> 0(실패), 1(성공) 예측 모델 만들어야함
치역: 어느 함수에서, 변수가 취할 수 있는 모든 값에 대하여 함수가 취할 수 있는 모든 값의 집합
특징
- 입력의 절대값이 커지면 0이나 1로 수렴 (치역은 0, 1)
- 중심이 원점이 아님
-> 기울기 소실 문제를 해결하기 위해 다른 활성화 함수가 등장
하이퍼볼릭 탄젠트 함수
쌍곡선 함수 중 하나로, 쌍곡선 함수는 삼각함수와 유사한 성질을 가지고, 표준 쌍곡선을 매개변수로 표시할 때 나오는 함수
하이퍼볼릭 탄젠트는 시그모이드 함수의 범위르 -1에서 1로 확장한 개념
ReLU
시그모이드부터 탄젠트 함수까지 해결되지 않았던 기울기 소실 문제를 해결
비선형 함수이고 음수에선 0, 양수에선 y=x값으로 전 구간에 미분값이 존재하기 때문에 학습이 가능함
특정 양수 값에 수렴하지 않아서 심층 신경망에서 시그모이드보다 더 잘 작동
연산이 필요 없어 속도 빠름
단점: 특정 출력이 0이면 여태껏의 gradient 값에 0을 곱해서 0이 되어버림
-> 죽은 ReLu
변형함수인 Leaky ReLU와 PReLU 등장
Leaky ReLu
입력값이 음수일 때 0이 아니라 0.01같이 작은 값을 반환하도록 하는 함수
PReLU
0 이전에는 학습 매개변수 a가 곱해져 조금씩 증가하다가 0부터는 y=x 직선형태를 가짐
ELU (Exponential Linear Unit Function)
Dying ReLU를 해결하기 위해 나온 함수
a는 하이퍼 파라미터 (보통 1)
출력값의 중심이 거의 0에 가까움
exp(지수함수)를 계산해야 해서 연산 비용이 커서 잘 사용하지 않음
Softmax 함수
출력층에서 사용하는 함수
다중 분류에 사용
iris 데이터는 4차원의 벡터를 -> 3차원 벡터로 줄이는 과정(분류하고자 하는 클래스의 개수)
마지막 층에 softmax를 투과하면 확률 값으로 나누어져나오고 그 총합은 1임
- 오차계산
예측값과 실제값의 차이는 1(y값) - 0.7(확률) =0.3 이런 방식이 아니라, cross entropy 함수를 통과시켜 나온 값
각 원소는 0~1 사이 값을 가짐
각각은 특정 클래스가 정답일 확률을 나타냄
실제값의 표현은 원핫 벡터로 표현
원핫벡터란? 단어 집합의 크기를 벡터의 차원으로 하고, 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고, 다른 인덱스에는 0을 부여하는 벡터표현 방식
소프트맥스 회귀는 (cross entropy 사용) 손실함수가 최소화 되는 방향으로 가중치를 업데이트 함 (역전파를 통해)
실제값(p), 예측값(q)
H(p, q) = cross entropy
0.70, 1.0 일때
-(1.0 x log(0.7))
+(0.0 x log(0.2))
+(0.0 x log(0.04))
0.1549
0.51
0.51
1.20
(0.51+0.51+1.20) / 3 = 0.74
손실함수(Loss Function)
• 예측값과 실제값의 차이를 구하는 함수
• 두 값의 차이가 클 수록 손실함수의 값은 커짐
• 두 값의 차이가 작을수록 손실함수의 값도 작아짐
역전파(Backpropagation)
• 오차예측값과 실제값의 차이를 역방향으로 전파시키면서(출력층 → 은닉층 → 입력층) 가중치를업데이트하는 것
가중치를 수정할 때에는 순전파에서 계산한 결과 y =f(x)의 편미분값을 오차에 곱해 출력층 → 은닉층 → 입력층 순서로 전달함
DFN 심층 순방향 신경망
기본 신경망, 레이어는 2개 이상
• 순방향이라 부르는 이유 : 데이터가 입력층→은닉층→출력층 순으로 전파되기 때문
RNN 순환 신경망
Time Series 데이터를 처리하기 위한 인공 신경망
LSTM(Long Short-Term Memory)
신경망 내에 메모리를 두어 과거의 먼 데이터도 저장
- 메모리 셀에는 망각 게이트가 들어감
- 입력 게이트: 현재 정보를 기억하기 위한 소자
- 망각 게이트: 과거의 정보를 어느정도까지 기억할 지 결정하는 소자
- 출력 게이트: 출력층으로 출력할 정보의 양을 결정하는 소자
CNN 합성곱 신경망
인간의 시각 처리 방식을 모방한 신경망
- 합성곱층 convolutional layer
- filter을 이용해 feature 추출
- 컨볼루셔널 레이어에 필터가 적용되면 특성 맵을 얻음
- ReLU 활성화 함수 사용
- 풀링층 pooling layer
- 특성맵을 입력으로 받아서 활성화 맵의 크기를 줄이거나, 특정 데이터를 강조
- ex ) 25x25를 14x14로 줄이기
- 최대 풀링(특성맵을 특성 크기로 만들고 가장 높은 값), 평균 풀링, 최소 풀링 3가지
- 완전 연결층 fully connected layer
- 합성곱층과 풀링층으로 추출한 특징을 분류하는 역할
- 합성곱층에서 특징만 학습하기 때문에 가중치의 수가 적어서 학습/예측이 빠름
- 1차원 배열로 연결해줌
convolutional layer에서 특징추출하고 pooling에서 축소하고 특징 추출하고 pooling에서 축소해서 fully connected layer에서 softmax 활성화 함수를 사용하고 1차원으로 연결시켜서 결괏값 도출
워드 임베딩
단어를 벡터로 표현하는 방법
원핫인코딩: N개의 단어를 N차원의 벡터로 표현하는 방식
단어가 포함되는 자리에는 1, 나머지에는 0이 들어감
Word2Vec: 비슷한 콘텍스트에 등장하는 단어들은 유사한 의미를 가진다는 이론에 기반하여 단어를 벡터로 표현해 주는 기법
CBOW: 전체 콘텍스트로부터 특정 단어 예측 (토익 빈칸 맞추기)
Skip-gram 특정 단어로부터 전체 콘텍스트의 분포(확률)을 예측
TF-IDF: 단어마다 가중치를 부여하여 단어를 벡터로 변환하는 방법
- TF(term frequency): 특정 문서에서 특정 단어가 등장하는 횟수
- DF(Document frequency): 특정 단어가 등장한 문서의 수
- IDF(Inverse document frequency): DF에 반비례하는 수(역수)
ex) TF= 5, DF=3, IDF=1/3
Fasttext
페이스북에서 개발한 워드 임베딩 방법으로
단어를 벡터로 변환하기 위해 부분 단어(sub words)라는 개념 도입
- N-gram: 문자열에서 N개의 연속된 요소를 추출하는 방법
- 단어는 띄어쓰기로 구분
모르는 단어 문제를 해결할 수 있기 때문에 임베딩에서 많이 사용됨
GAN 적대적 생성 신경망
2개의 신경망 모델이 서로 경쟁하면서 더 나은 결과를 만들어내는 강화학습
이미지 생성에 뛰어난 성능
생성모델(generator Model) : 주어진 데이터와 최대한 유사한 가짜 데이터 생성
판별 모델(Discriminator Model): 진짜 데이터와 가짜 데이터 중 어떤 것이 진짜 데이터인지를 판별
ex) 위조지폐범 vs 경찰
Summary
퍼셉트론이 쌓이면서 다중 퍼셉트론이 쌓이고
심층망이 깊어지며 deep learning이 나옴
RNN, CNN, DFN, GAN 등 여러 신경망이 등장
'Education > ICT AI 중급' 카테고리의 다른 글
| 3주차_10 필기 (파이토치 배열) (1) | 2023.10.15 |
|---|---|
| 2주차_09 필기 (파이토치 MNIST MLP tensorboard) (1) | 2023.10.15 |
| 2주차_08 필기 (데이터 처리 및 파이토치) (1) | 2023.10.15 |
| 2주차_07 필기 (텐서플로우) (0) | 2023.10.15 |
| 1주차_04 필기 (ML 개요) (1) | 2023.10.15 |