728x90
ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models
Abstract
ReWOO (Reasoning Without Observation): 추론 과정을 외부 도구 관찰과 분리하는 새로운 모듈형 패러다임 제안
기존 ALM 시스템 문제: 추론과 도구 호출을 교차 수행 → 토큰 사용량 증가, 계산 비용 상승
ReWOO의 핵심: 추론과 도구 호출을 분리해 비효율성 최소화
HotpotQA 벤치마크에서 5배 토큰 효율성 + 4% 정확도 향상
도구 오류 상황에서도 안정적인 성능 유지
추론 능력을 작은 모델(7B LLaMA)로 이전 가능 → 대규모 모델(GPT-3.5 175B) 의존성 감소
ReWOO는 효율적이고 확장 가능한 ALM 구축 가능성을 보여줌
1 Introduction
배경
- LLM(대규모 언어 모델)과 외부 도구(플러그인)를 결합해 최신 정보를 검색하고 환경과 상호작용하는 ALM(증강 언어 모델)이 주목받는 중.
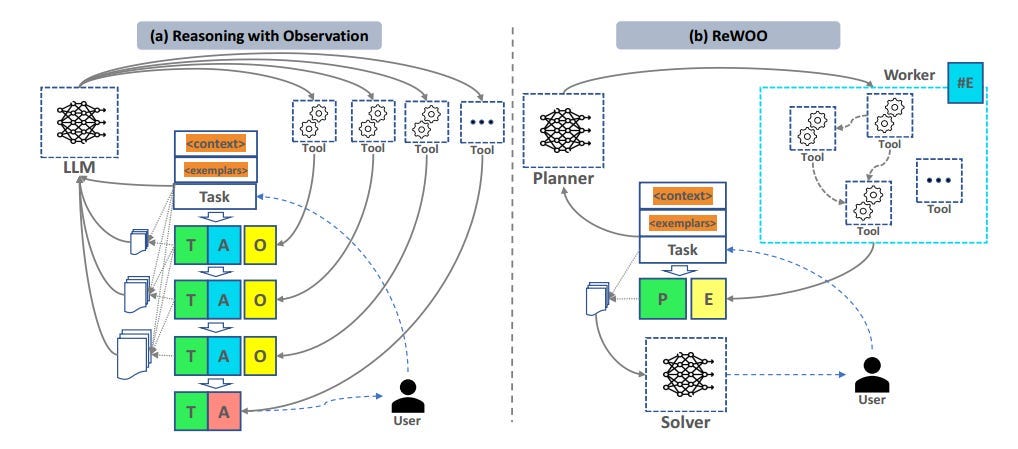
- 기존 ALM 시스템은 ReAct 방식으로 추론과 도구 호출을 교차 수행 → 토큰 사용량 과다 및 계산 비용 증가 문제 발생.
- OpenAI 같은 상용 LLM은 토큰 사용량 기반으로 과금 → 프롬프트 중복이 사용자 비용 증가로 이어짐.
- 문제 해결
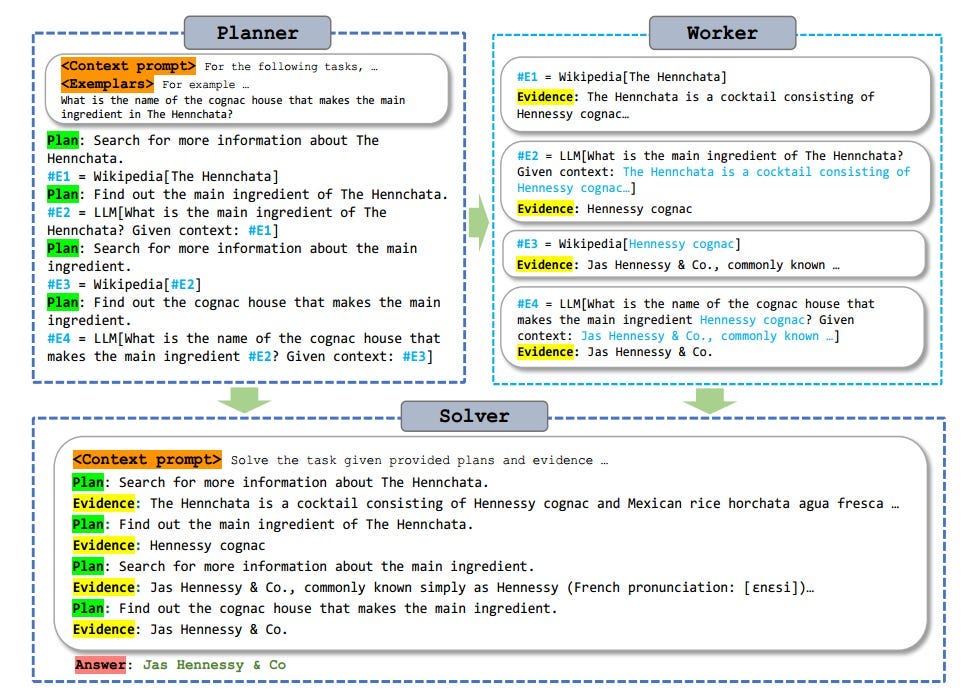
- ReWOO (Reasoning Without Observation) 제안: ALM의 추론, 도구 호출, 요약 작업을 Planner, Worker, Solver 3개 모듈로 분리함.
- Planner: 작업을 세분화하고 계획을 수립.
- Worker: 외부 도구로부터 필요한 증거 검색.
- Solver: 계획과 증거를 종합해 최종 답안 생성.
- 기존 방식의 프롬프트 중복 문제 해결 → 토큰 사용량 절감 + 효율성 향상.
- ReWOO (Reasoning Without Observation) 제안: ALM의 추론, 도구 호출, 요약 작업을 Planner, Worker, Solver 3개 모듈로 분리함.
- 실험 결과
- 6개 NLP 벤치마크 + 맞춤형 데이터셋에서 ReWOO 성능 평가.
- 기존 ALM 방식인 ReAct 대비 토큰 효율성 증가 + 성능 향상 확인.
- LLaMA 7B 모델을 소규모 학습으로 GPT-3.5와 유사한 성능 달성 → 경량 모델 활용 가능성 입증.
- 기여
- 추론 능력 분석: 명시적 관찰 없이도 LLM의 추론 능력을 활용해 프롬프트 효율적인 ALM 구현 가능성 제시.
- 모듈형 프레임워크: ReWOO를 통해 기존 ALM 대비 토큰 사용량 절감 + 성능 향상 + 강건성 증가.
- 경량화 가능성: LLM 추론 능력을 작은 모델로 이전해 경량화 및 확장성 지원.
- 의의
- ReWOO는 기존 ALM의 한계를 극복하며, 효율적이고 확장 가능한 ALM 시스템 개발에 기여 가능성을 보여줌.
2 Methodology
2.1 ReWOO with Plan-Work-Solve Paradigm
- Planner: LLM의 예측 추론(foreseeable reasoning)을 활용해 작업 계획(blueprint) 수립.
- 계획은 연속적인 (Plan, #E) 튜플로 구성 (#E는 증거 저장용 토큰).
- 이전 단계의 #E를 다음 단계 Worker에게 전달해 다단계 및 복잡한 작업 처리 가능.
- Worker: Planner가 수립한 계획에 따라 외부 도구 호출 → 실질적인 증거(#E)를 채움.
- Solver: Planner와 Worker가 생성한 계획과 증거를 바탕으로 최종 솔루션 도출.
- "주의 깊게" 사용 지시 시 성능 향상 관찰됨 → Planner/Worker 실패 보완 가능.
2.2 Prompt Redundancy Reduction

- 기존 ALM은 추론-도구 호출-관찰(TAO) 패턴 반복 → 프롬프트 중복으로 토큰 사용량 폭증.
- 질문(Q) + 컨텍스트(C) + 예제(S)를 기반으로 k번 추론 시, 입력 토큰이 선형이 아닌 제곱(k²) 수준 증가.
- 결과적으로 계산 비용, 토큰 한계 초과, 시간 소모 증가.
- ReWOO는 Plan, Evidence(#E), 실제 증거(E)를 사용해 이러한 중복을 방지.
- 토큰 사용량이 선형적으로 감소해 복잡한 작업에서 비용 절감 효과 큼.
2.3 Parameter Efficiency by Specialization
- 기존 ALM은 파라미터 모델(LLM)과 비파라미터 도구 호출 결합으로 훈련 복잡성 증가.
- Toolformer: 도구 활용 데이터를 기반으로 LLM을 미세 조정 → 다단계 추론엔 한계.
- ReAct: 추론 과정(TAO) 학습 → 새로운 작업/도구로의 일반화 부족.
- ReWOO의 접근:
- 추론을 도구 호출과 분리 → Planner 모듈에서 예측 추론 최적화 가능.
- GPT-3.5를 활용해 (Plan, #E) 블루프린트 생성 → LLaMa 7B로 오프로딩하여 경량화된 Planner 7B 제작.
- 알파카(Alpaca) 7B: GPT-3.5의 일반적 추론 능력을 재현하도록 미세 조정 후 Planner에 특화.
- 결과: 여러 벤치마크에서 Planner를 GPT-3.5, Alpaca 7B, Planner 7B로 대체해 성능 테스트 → 경량 모델로도 높은 성능 달성.
3 Experiments
3.1 Setups
- 평가 대상: ReWOO와 최신 프롬프트 패러다임 비교 (ReAct, CoT 등).
- 데이터셋:
- 일반 지식/추론: HotpotQA(다중 단계 QA), TriviaQA(독해 기반 도전적 QA), SportsUnderstanding(스포츠 도메인 QA), StrategyQA(추론 기반 QA).
- 수학/과학 추론: GSM8K(초등 수학), PhysicsQuestions(고등학교 물리).
- 커스텀: SOTUQA(2023 국정연설 QA, 최신 지식 활용), 실생활 기반 작업(ex: 식당 추천, 주식 거래 등).
- 비교 기준:
- Direct Prompt: 도구 없이 직접 해결 (기본 성능 확인).
- Chain-of-Thought (CoT): 단계별 추론을 유도해 중간 추론 과정을 나타냄.
- ReAct: 도구 호출과 추론을 교차 수행.
- 평가 지표:
- 정확도(EM, F1) + GPT-4 기반 의미 정확도.
- 효율성: LLM 토큰 사용량, 추론 단계 수, 1k 쿼리당 비용(USD).
3.2 Results and Observations
(1) 프롬프트 패러다임 비교
- ReWOO가 ReAct를 모든 벤치마크에서 일관적으로 능가.
- 평균적으로 토큰 사용량 64% 감소, 정확도 4.4% 상승.
- SOTUQA에서 ReWOO는 ReAct 대비 정확도 8% 상승, 토큰 43% 절감.
- ReWOO의 효율성 → 복잡한 작업에서도 추론 능력 강화 및 비용 절감 입증.
(2) 도구의 영향
- 불필요한 도구가 ALM 성능 저하 가능.
- 도구 개수가 늘어날수록 정확도 감소 경향.
- 부적절한 도구 사용(예: Yelp로 유명인 검색) 사례 발견.
(3) 도구 실패 상황에서의 강건성
- ReWOO는 도구 오류(“No evidence found”) 상황에서도 상대적으로 안정적.
- ReAct는 도구 오류에 크게 취약.
(4) RLHF(강화학습 미세조정)
- text-davinci-003이 gpt-3.5-turbo 대비 단계 수 적고 효율적.
- RLHF가 ALM의 상식적 추론 능력에 약간 부정적 영향을 줄 가능성.
3.3 Fine-tuning and Specialization of LLM
- Planner 7B: GPT-3.5의 예측 추론 능력을 Alpaca 7B로 오프로딩 → HotpotQA, TriviaQA에서 GPT-3.5 성능에 근접.
- 효과:
- Planner 7B가 Google, Calculator 등 새로운 도구와의 추론에서도 점진적 성능 향상 관찰.
- 경량 모델로 시스템 파라미터 효율성 및 확장성 대폭 개선 가능성 확인.
- 향후 과제: Specialization 한계를 극복하기 위한 추가 연구 필요.
6 Conclusion
ReWOO 제안:
- 추론과 도구 피드백(관찰)을 분리하여 다단계 추론 작업을 효율적으로 해결하는 모듈형 ALM 프레임워크.
핵심 성과:
- 기존 Thought-Action-Observation 방식의 프롬프트 중복 문제를 이론적으로 분해 → 토큰 사용량 대폭 감소.
- 공개 NLP 벤치마크 + 커스텀 작업에서 ReWOO가 성능 및 효율성 모두 우수함을 입증.
- 도구 오류 상황에서도 상대적으로 강건한 성능 관찰.
추가 발견:
- Instruction Tuning과 Specialization을 통한 일반 추론 능력의 경량화 및 오프로딩 가능성 확인.
향후 과제:
- 모듈형 LLM 미세조정, 도구 표현 학습, 시스템 그래프 학습 및 최적화를 포함한 ALM 시스템의 발전 가능성.
의의:
- ReWOO는 확장 가능한 AGI로의 발전에 기여할 탄탄한 기초를 마련함.
반응형
'AI > Papers' 카테고리의 다른 글
| Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks (0) | 2024.11.15 |
|---|---|
| Recommender Systems with Generative Retrieval - High-level Summary (0) | 2024.10.25 |